数据结构
栈(Stack)¶
介绍¶

栈(Stack)是 OI 和日常编程中常见的一种线性数据结构,其特点是 先进后出(LIFO)。
想象一下手枪弹夹上弹的过程,先压入的子弹在最底部,最后压入的子弹最先打出🔫。
栈的实现¶
数组模拟栈
int stk[N];
int top = 0; // 栈顶下标,top = 0 表示空栈
- 加入元素:
stk[++top] = x; - 弹出栈顶:
if (top > 0) top--; - 查看栈顶:
if (top > 0) cout << stk[top]; - 获取栈大小:
cout << top; - 清空栈:
top = 0;
✅ 优点:可以直接访问任意位置,清空快,效率高。
模板题代码实现
参考代码
#include <bits/stdc++.h>
#define ull unsigned long long
#define ll long long
using namespace std;
ull stk[1000005];
int main()
{
ios::sync_with_stdio(false);
cin.tie(0); // 不要用 endl,换行用 \n
int t;
cin >> t;
while (t--)
{
int n;
cin >> n;
int top = 0; // 代表栈顶,也起到了多组数据清空栈的作用
for (int i = 1; i <= n; i++)
{
string op;
cin >> op;
if (op == "push")
{
ull x;
cin >> x;
stk[++top] = x;
}
if (op == "pop")
{
if (top > 0) top--; // 删除栈顶
else cout << "Empty\n";
}
if (op == "query")
{
if (top > 0) cout << stk[top] << "\n";
else cout << "Anguei!\n";
}
if (op == "size")
{
cout << top << "\n";
}
}
}
return 0;
}
STL stack 实现
#include <stack>
stack<int> stk;
| 函数 | 作用 | 示例 | 注意事项 |
|---|---|---|---|
push(x) |
入栈 | stk.push(5); |
函数无返回值。 |
pop() |
出栈 | stk.pop(); |
函数无返回值。保证栈不为空才能使用,否则 RE。 |
top() |
获取栈顶元素 | stk.top(); |
返回值取决于栈的类型。 保证栈不为空才能使用,否则 RE。 |
size() |
获取大小 | stk.size(); |
返回值为 unsigned int 类型。 |
empty() |
判空 | stk.empty(); |
返回值为 bool,true 代表空,false 代表不空。 |
🧹 清空栈:
while (!stk.empty()) stk.pop();
模板题代码实现
参考代码
#include <bits/stdc++.h>
#define ull unsigned long long
#define ll long long
using namespace std;
int main()
{
ios::sync_with_stdio(false);
cin.tie(0); // 不要用 endl,换行用 \n
int t;
cin >> t;
while (t--)
{
int n;
cin >> n;
stack<ull> stk;
for (int i = 1; i <= n; i++)
{
string op;
cin >> op;
if (op == "push")
{
ull x;
cin >> x;
stk.push(x);
}
if (op == "pop")
{
if (!stk.empty()) stk.pop(); // 删除栈顶
else cout << "Empty\n";
}
if (op == "query")
{
if (!stk.empty()) cout << stk.top() << "\n";
else cout << "Anguei!\n";
}
if (op == "size")
{
cout << stk.size() << "\n";
}
}
}
return 0;
}
🆚 对比:
- 数组模拟效率更高;
- STL 使用更方便、易读;
- 实战中根据习惯选择即可。
判断入栈序列是否合法¶
方法: 模拟整个过程,遇到不合法顺序即判定失败。
例题:
入栈序列:a b c d e
出栈选项:
a b c d e✅e d c b a✅b a c d e✅c d a e b❌ (a不可能先于b离开)
表达式相关概念¶
算术表达式主要有三种形式:
- 中缀表达式:运算符位于操作数之间,例如
a + b,这是我们日常书写方式。 - 后缀表达式(逆波兰表达式):运算符在操作数之后,例如
a b +。 - 前缀表达式(波兰表达式):运算符在操作数之前,例如
+ a b。
后缀和前缀表达式的优点是无需括号就能唯一确定运算顺序,非常适合用栈进行求值和转换。
中缀 → 后缀
方法(栈法):
- 从左到右扫描表达式:
- 数字或操作数 $→$ 直接输出
- 左括号
(→ 入栈 - 右括号
)→ 弹栈直到遇到左括号,左括号丢弃 - 运算符 $→$ 弹出栈顶所有优先级 $\geq$ 当前运算符的元素,输出,再将当前运算符入栈
- 扫描结束后,将栈内剩余运算符依次输出
例题:
中缀表达式:a * (b + c) * d 转换步骤:
- 扫描
a→ 输出:a - 扫描
*→ 入栈 - 扫描
(→ 入栈 - 扫描
b→ 输出:a b - 扫描
+→ 入栈 - 扫描
c→ 输出:a b c - 扫描
)→ 弹栈+输出 →a b c + - 扫描
*→ 弹栈*输出 → 再入栈新* - 扫描
d→ 输出 →a b c + d - 扫描结束 → 弹栈
*→ 输出:a b c + d * *✅
中缀 → 前缀
方法(栈法 + 逆序):
- 将中缀表达式逆序(从右到左扫描)
- 替换左右括号:
(↔) - 使用和中缀→后缀相同的规则(栈法)生成 “逆序后缀”
- 最后将结果逆序得到前缀表达式
例题:
中缀表达式:a + (b - c) * d
- 逆序:
d * (b - c) + a - 括号替换:
d * (b - c) + a→d * (b - c) + a(这里左右括号变了方向,但在公式中效果相同) - 后缀生成(逆序后缀):
d b c - * a + - 逆序 → 前缀:
+ a * - b c d✅
后缀 → 中缀
方法(栈法):
- 从左到右扫描后缀表达式:
- 遇到操作数 → 入栈
- 遇到运算符 → 弹出栈顶两个元素,组合成中缀子表达式
(左 操作符 右),再入栈。(先出栈的是右,后出栈的是左)
- 扫描结束,栈顶即为完整中缀表达式
例题:
后缀表达式:6 2 3 + - 3 8 2 / + * 2 ^ 3 +
6入栈2入栈3入栈+→ 弹出2, 3→ 组合为(2 + 3)入栈-→ 弹出6, (2 + 3)→ 组合为(6 - (2 + 3))入栈3入栈8入栈2入栈/→ 弹出8, 2→ 组合为(8 / 2)入栈+→ 弹出3, (8 / 2)→ 组合为(3 + 8 / 2)入栈*→ 弹出(6 - (2 + 3)), (3 + 8 / 2)→ 组合为((6 - (2 + 3)) * (3 + 8 / 2))入栈2入栈^→ 弹出2, ((6 - (2 + 3)) * (3 + 8 / 2))→ 组合为((6 - (2 + 3)) * (3 + 8 / 2)) ^ 2入栈3入栈+→ 弹出3, ((6 - (2 + 3)) * (3 + 8 / 2)) ^ 2→ 组合为((6 - (2 + 3)) * (3 + 8 / 2)) ^ 2 + 3✅
担心记忆出错,可以使用
a - b的后缀a b -来验证。
前缀 → 中缀
方法(栈法):
- 从右到左扫描前缀表达式:
- 遇到操作数 → 入栈
- 遇到运算符 → 弹出栈顶两个元素,组合成中缀子表达式
(左 操作符 右),入栈(先出栈的是左,后出栈的是右)
- 扫描结束,栈顶即为完整中缀表达式
例题:
前缀表达式:+ a * - b c d
- 右到左扫描
- 操作数
d、c、b、a入栈 -→ 弹出b, c→(b - c)入栈*→ 弹出(b - c), d→((b - c) * d)入栈+→ 弹出a, ((b - c) * d)→(a + ((b - c) * d))✅
- 操作数
担心记忆出错,可以使用
a - b的后缀- a b来验证。
队列(Queue)¶
介绍¶

队列(queue)是一种先进先出(FIFO, First In First Out)的线性数据结构。简单地说:谁先来,谁先走! ✅
👀 类比:
- 排队买奶茶,先到的人先买完走。
- 打印任务,先提交的先打印。
实现方式¶
使用数组 + 双指针(头指针
h、尾指针t)模拟队列操作。
const int N = 100010;
int q[N];
int h = 1, t = 0; // 初始状态,队列为空
📌 操作说明:
| 操作 | 代码 | 说明 |
|---|---|---|
| 插入元素 | q[++t] = x; |
将元素加入队尾 |
| 删除队头 | h++; |
队头元素出队 |
| 获取队头 | q[h]; |
查看队头元素 |
| 获取队尾 | q[t]; |
查看队尾元素 |
| 队列大小 | t - h + 1; |
当前队列中元素个数 |
| 清空队列 | h = 1, t = 0; |
恢复初始状态 |
完整代码
#include <bits/stdc++.h>
using namespace std;
const int N = 1e4 + 5;
int q[N], h = 1, t = 0, n;
int main()
{
ios::sync_with_stdio(false);
cin.tie(0); // 不要用 endl,换行用 \n
cin >> n;
while (n--)
{
int op, x;
cin >> op;
if (op == 1)
{
cin >> x;
q[++t] = x;
}
if (op == 2)
{
if (h <= t) h++;
else cout << "ERR_CANNOT_POP\n";
}
if (op == 3)
{
if (h <= t) cout << q[h] << "\n";
else cout << "ERR_CANNOT_QUERY\n";
}
if (op == 4)
{
cout << t - h + 1 << "\n";
}
}
return 0;
}
STL queue
#include <queue>
using namespace std;
queue<int> q;
🔧 常用操作:
| 函数 | 说明 | 注意事项 |
|---|---|---|
q.push(x) |
插入元素到队尾 | 函数无返回值。 |
q.pop() |
删除队头元素(需保证非空) | 函数无返回值。保证队列不为空才能使用,否则 RE。 |
q.front() |
查看队首元素 | 返回值取决于队列的类型。 保证队列不为空才能使用,否则 RE。 |
q.back() |
查看队尾元素 | 返回值取决于队列的类型。 保证队列不为空才能使用,否则 RE。 |
q.size() |
获取队列大小 | 返回值为 unsigned int 类型。 |
q.empty() |
检查队列是否为空 | 返回值为 bool,true 代表空,false 代表不空。 |
🧹 清空队列:
while (!q.empty()) q.pop();
模板题代码实现
完整代码
#include <bits/stdc++.h>
using namespace std;
int n;
queue<int> q;
int main()
{
ios::sync_with_stdio(false);
cin.tie(0); // 不要用 endl,换行用 \n
cin >> n;
while (n--)
{
int op, x;
cin >> op;
if (op == 1)
{
cin >> x;
q.push(x);
}
if (op == 2)
{
if (!q.empty()) q.pop();
else cout << "ERR_CANNOT_POP\n";
}
if (op == 3)
{
if (!q.empty()) cout << q.front() << "\n";
else cout << "ERR_CANNOT_QUERY\n";
}
if (op == 4)
{
cout << q.size() << "\n";
}
}
return 0;
}
初赛考察点¶
- 队列操作选择题
- BFS 广度优先搜索算法的常用数据结构是队列。
链表(Linked List)¶
介绍¶
链表是一种用于存储数据的数据结构,通过如链条一般的指针来连接元素。它的特点是插入与删除数据十分方便,但寻找与读取数据的表现欠佳。
与数组的区别
链表和数组都可用于存储数据。与链表不同,数组将所有元素按次序依次存储。不同的存储结构令它们有了不同的优势:
链表因其链状的结构,能方便地删除、插入数据,操作次数是 $O(1)$。但也因为这样,寻找、读取数据的效率不如数组高,在随机访问数据中的操作次数是 $O(n)$。
数组可以方便地寻找并读取数据,在随机访问中操作次数是 $O(1)$。但删除、插入的操作次数是 $O(n)$ 次。
单向链表¶
单向链表中包含数据域和指针域,其中数据域用于存放数据,指针域用来连接当前结点和下一节点。

struct Node
{
int value;
Node *next;
};
$x$ 的后面插入 $y$
y->next = x->next;
x->next = y;
删除 $x$ 的下一个节点
x->next = x->next->next;
双链表¶
双向链表中同样有数据域和指针域。不同之处在于,指针域有左右(或上一个、下一个)之分,用来连接上一个结点、当前结点、下一个结点。

struct Node
{
int value;
Node *left;
Node *right;
};
$x$ 的后面插入 $y$
y->next = x->next;
y->next->prev = y;
y->prev = x;
x->next = y;
删除节点 $y$ 的
y->prev->next = y->next;
y->next->prev = y->prev;
例题:
在双向循环链表中,节点 p 后插入 s。正确操作:
s->prev = p;s->next = p->next;p->next->prev = s;p->next=s;✅
初赛考察点¶
- 链表的特点(通常和数组比较)
- 插入/删除代码理解
- 头插法、尾插法
图¶
介绍¶
图是一个二元组 $G = (V, E)$,其中:
- $V(G)$:非空集合,称为点集(vertex set),其元素为顶点(vertex)或节点(node)。
- $E(G)$:顶点对之间的集合,称为边集(edge set),其元素称为边(edge)。
图分为以下几类:
- 无向图(Undirected Graph):$E$ 中每个元素是无序对 $(u, v)$。
- 有向图(Directed Graph):$E$ 中每个元素是有序对 $(u, v)$,也写作 $u \to v$。
- 混合图(Mixed Graph):同时包含有向边和无向边。
简单图与多重图
- 自环(Loop):边的两个端点相同,即 $(v, v)$。
- 重边(Multiple Edge):存在两个完全相同的边(在无向图中,$(u, v)$ 与 $(v, u)$ 视为相同)。
- 简单图(Simple Graph):无自环和重边的图。
- 多重图(Multigraph):包含自环或重边的图。
度数(Degree)
- 无向图中,顶点 $v$ 的度记作 $d(v)$,表示与 $v$ 相连的边数。
- 有向图中:
- 出度:从 $v$ 出发的边数,记作 $d^+(v)$。
- 入度:以 $v$ 为终点的边数,记作 $d^-(v)$。
- 有 $d(v) = d^+(v) + d^-(v)$。
- 握手定理:对于无向图,有
推论:奇点数量一定为偶数。
连通性(Connectivity)
无向图
- 连通:若存在从 $u$ 到 $v$ 的路径。
- 连通图(Connected Graph):任意两点连通。
有向图
- 可达:存在从 $u$ 到 $v$ 的路径。
- 强连通图(Strongly Connected Graph):任意两点互相可达。
图的存储¶
在 OI(信息学竞赛)中,图论是重要的内容,而要对图进行高效操作,必须掌握不同的图的存储方法。
一、直接存边
使用结构体或多个数组存储边:每条边包含起点、终点和边权。
关键代码
struct edge
{
int u, v, w; // 起点、终点、边权
} e[M]; // M 是边的上限
int main()
{
int n, m;
cin >> n >> m;
for (int i = 1; i <= m; i++)
{
cin >> e[i].u >> e[i].v >> e[i].w;
}
return 0;
}
二、邻接矩阵
使用二维数组 adj[u][v] 表示 $u \to v$ 是否有边,或存储边权。
关键代码
int adj[N][N];
int main()
{
int n, m;
cin >> n >> m;
for (int i = 1; i <= m; i++)
{
int u, v;
cin >> u >> v;
adj[u][v] = 1; // 无向图则同时设 adj[v][u] = 1;
}
// 若为带边权图:
for (int i = 1; i <= m; i++)
{
int u, v, w;
cin >> u >> v >> w;
adj[u][v] = w; // 无向图设 adj[v][u] = w;
}
return 0;
}
三、邻接表
使用 vector 动态数组存储每个点的出边。
关键代码
vector<int> e[N]; // 不带权
vector<pair<int, int>> g[N]; // 带边权
int main()
{
int n, m;
cin >> n >> m;
for (int i = 1; i <= m; i++)
{
int u, v;
cin >> u >> v;
e[u].push_back(v); // 无向图加 e[v].push_back(u)
}
// 带边权
for (int i = 1; i <= m; i++)
{
int u, v, w;
cin >> u >> v >> w;
g[u].emplace_back(v, w);
// 无向图加 g[v].emplace_back(u, w)
}
return 0;
}
四、链式前向星
链式前向星是一种使用数组模拟链表实现的邻接表,支持快速存储和遍历边。其核心思想类似于 链表的头插法。
关键代码
struct edge
{
int to, nxt, w;
} e[M];
int head[N], idx = 0; // head[u] 是点 u 的第一条出边的编号
void add(int u, int v, int w)
{
e[++idx] = {v, head[u], w}; // 新边插入到 u 的出边链表头部
head[u] = idx; // 更新 u 的第一条边为新插入的这条
}
int main()
{
int n, m;
cin >> n >> m;
for (int i = 1; i <= m; i++)
{
int u, v, w;
cin >> u >> v >> w;
add(u, v, w); // 有向图
// add(v, u, w); // 若为无向图,需要加一条反向边
}
return 0;
}
链表头插法讲解
以点 $u$ 的出边为一个链表,每次新加边 $u \to v$,就像在链表头部插入一个新节点:
e[++idx] = {v, head[u], w}新建一条边,指向之前的第一条边。head[u] = idx更新链表头。
这样,点 $u$ 的所有出边就构成了一个链表,链表中的每一条边都通过 nxt 指向下一条边。
遍历方式如下:
for (int i = head[u]; i; i = e[i].nxt)
{
int v = e[i].to;
int w = e[i].w;
// 使用 v 和 w 做操作
}
图的遍历¶
DFS(深度优先搜索)简介
DFS 全称是 Depth First Search,中文名是深度优先搜索,是一种用于遍历或搜索树或图的算法。所谓深度优先,就是每次都尝试向更深的节点走。
DFS 过程说明
DFS 最大的特点是递归地访问每个未访问的相邻节点,同时为避免重复访问,会使用一个 visited 数组做标记。伪代码如下:
DFS(v):
vis[v] = true
for u in adj[v]:
if not vis[u]:
DFS(u)
例题
以 $a$ 为起点,对右边的无向图进行深度优先遍历,则 $b、 c、 d、 e$ 四个点中有可能作 为最后一个遍历到的点的个数为( )。
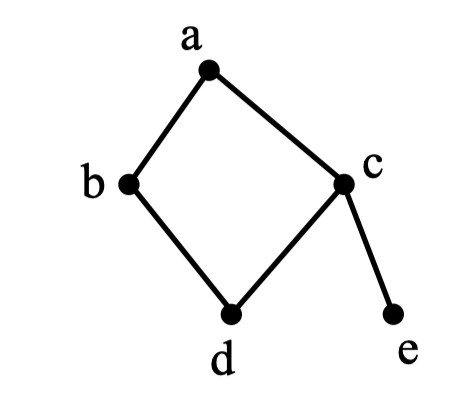
答案: 2
解析:
- 从 $a$ 开始,有两个邻点可以访问,假如先访问 $b$,根据 DFS 的特点,则会继续访问 $b$ 的邻点,即 $d$,然后是 $c$,最后是 $e$,此时 $e$ 是最后一个访问到的点。
- 假如先访问 $c$,则 $c$ 的邻点为 $d$ 和 $e$,不管先访问谁可以证明 $b$ 是最后一个访问的节点。
因此答案为 $2$。
BFS(广度优先搜索)简介
BFS 全称是 Breadth First Search,中文名是广度优先搜索。
BFS 每次尝试访问所有“同一层”的节点,之后再访问下一层。由于这样的层次性,它常被用来寻找最短路径(边权为 1)。
在上述例题中,如果从 $a$ 出发执行 BFS,则 $d,e$ 有可能是最后一个访问的节点。
拓扑排序¶
在大学的课程体系中,例如有:「程序设计」、「算法语言」、「高等数学」、「离散数学」、「编译技术」、「普通物理」、「数据结构」、「数据库系统」等课程。
有些课程有先修要求:
- 学「数据结构」之前必须完成「离散数学」。
- 有了「数据结构」的基础,才能继续学习「编译技术」。
这些课程可以看作图中的点(顶点),课程间的先修关系可视为图中的有向边。
教务处需要按照这些依赖关系,排出合理的课程顺序,使得每门课程的前置条件都已被满足。
这就是典型的 拓扑排序 问题。
拓扑排序(Topological Sorting) 是图论中的一种排序方法。
它的目标是对一个 有向无环图(DAG) 中的所有节点进行排序,使得对于每条有向边 $(u, v)$,节点 $u$ 排在节点 $v$ 的前面。
例题
考虑一个有向无环图,该图包含四条有向边:$(1,2)$, $(1,3)$, $(2,4)$ 和 $(3,4)$。以下哪个选项是这个有向无环图的一个有效的拓扑排序?()
画出图以后不难发现只有两个合法的拓扑排序分别是:
- $1\to 2\to 3\to 4$。
- $1\to 3\to 2\to 4$。
树(Tree)¶
图论中的树和现实生活中的树长得一样,只不过我们习惯于处理问题的时候把树根放到上方来考虑。这种数据结构看起来像是一个倒挂的树,因此得名。
介绍¶
一个没有固定根结点的树称为 无根树(unrooted tree)。无根树有几种等价的形式化定义:
有 $n$ 个结点,$n-1$ 条边的连通无向图
-
无向无环的连通图
-
任意两个结点之间有且仅有一条简单路径的无向图
-
任何边均为桥的连通图
-
没有圈,且在任意不同两点间添加一条边之后所得图含唯一的一个圈的图
在无根树的基础上,指定一个结点称为 根,则形成一棵 有根树(rooted tree)。有根树在很多时候仍以无向图表示,只是规定了结点之间的上下级关系,详见下文。
| 概念 | 说明 |
|---|---|
| 🌲 森林(forest) | 每个连通分量(连通块)都是树的图 |
| 🌿 生成树(spanning tree) | 一个连通无向图的生成子图,要求是树 |
| 🍃 叶结点(leaf node) | 对于无根树是度数 $\le 1$;有根树是没有子结点的节点 |
| 概念 | 说明 |
|---|---|
| 👨👧 父亲(parent) | 除根以外每个节点,从该节点到根路径上的第二个节点 |
| 🧓 祖先(ancestor) | 从该节点到根的路径上的节点(不含自身) |
| 👶 子结点(child) | 若 $u$ 是 $v$ 的父,则 $v$ 是 $u$ 的子 |
| 📏 深度(depth) | 到根的路径上的边数 |
| 🗻 高度(height) | 所有结点深度的最大值 |
| 🤝 兄弟(sibling) | 同一父结点下的多个子节点 |
| 🧬 后代(descendant) | 子节点及其后代 |
| 🌳 子树(subtree) | 删掉与父相连的边后该结点所在的子图 |

子树示意图:

特殊的树¶
| 类型 | 描述 |
|---|---|
| 📏 链(chain) | 每个结点的度数不超过 2 |
| 🌼 菊花/星星(star) | 存在 $u$,所有其他节点都与 $u$ 相连 |
| 🌲 有根二叉树 | 每个节点最多两个子结点 |
| 🌳 完整二叉树 | 每个节点要么没有子节点要么有两个 |
| 🧱 完全二叉树 | 只有最后两层可不满,最底层集中左侧 |
| 🏠 完美二叉树(满二叉树) | 所有叶节点深度相同,非叶节点都有两个子节点 |
- 🌳 完整二叉树(full/proper binary tree):每个节点要么没有子节点要么有两个

- 🧱 完全二叉树(complete binary tree):只有最下面两层结点的度数可以小于 $2$,且最下面一层的结点都集中在该层最左边的连续位置上。

- 🏠 完美二叉树(满二叉树)(perfect binary tree):所有叶结点的深度均相同,且所有非叶节点的子节点数量均为 2 的二叉树称为完美二叉树。
- 「满二叉树」多指完美二叉树。

树的存储¶
由于树是特殊的图,因此存储方式完全同上。
二叉树¶
二叉树的遍历
由于二叉树最多只有两个子节点,在存储时记录左右儿子编号。根据遍历左右儿子的访问顺序不同,通常分为以下三种遍历方式。
先序遍历¶
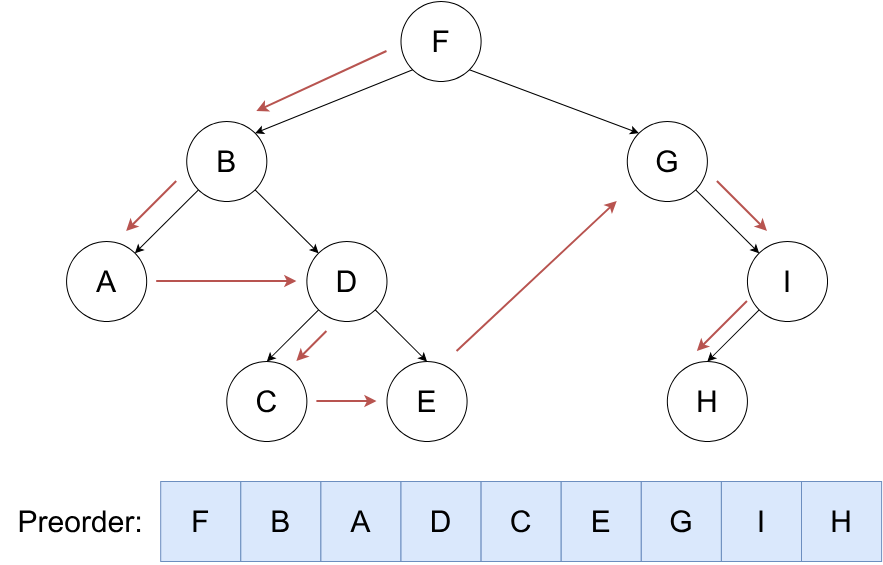
按照 根,左,右 的顺序遍历二叉树。
void dfs(int u)
{
cout << u << " ";
if (lson[u]) dfs(lson[u]);
if (rson[u]) dfs(rson[u]);
}
中序遍历¶
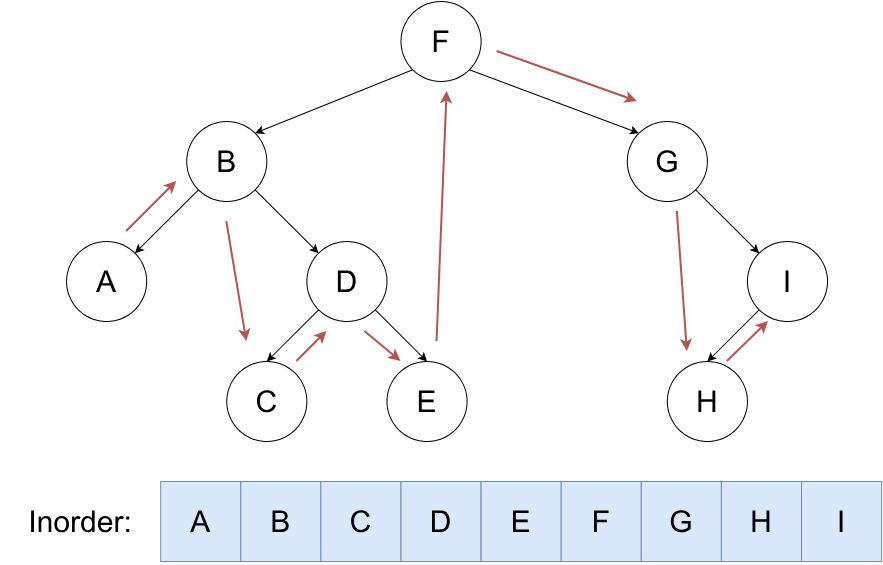
按照 左,根,右 的顺序遍历二叉树。
void dfs(int u)
{
if (lson[u]) dfs(lson[u]);
cout << u << " ";
if (rson[u]) dfs(rson[u]);
}
后序遍历¶
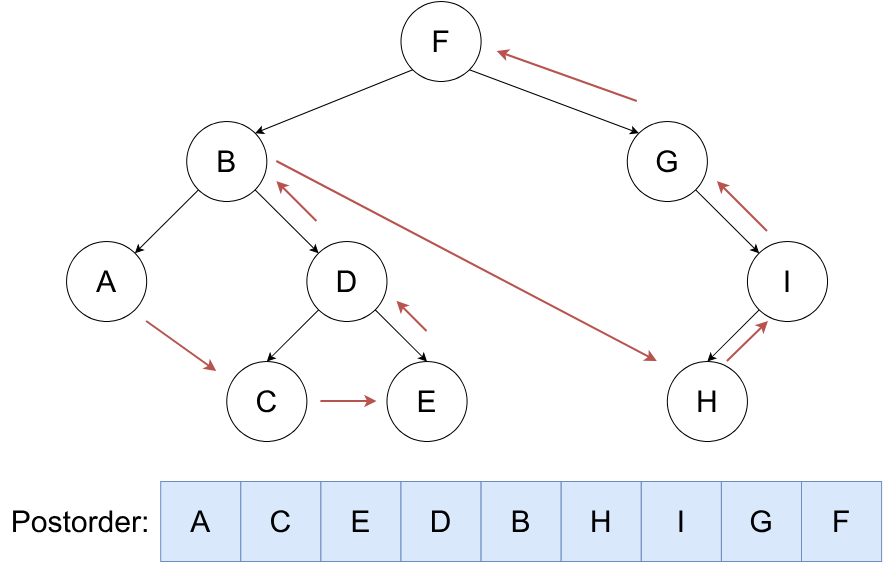
按照 ,右,根 的顺序遍历二叉树。
void dfs(int u)
{
if (lson[u]) dfs(lson[u]);
if (rson[u]) dfs(rson[u]);
cout << u << " ";
}
总结¶
| 遍历 | 顺序 | 代码 |
|---|---|---|
| 前序 | 根 → 左 → 右 | cout → dfs(l) → dfs(r) |
| 中序 | 左 → 根 → 右 | dfs(l) → cout → dfs(r) |
| 后序 | 左 → 右 → 根 | dfs(l) → dfs(r) → cout |
反推¶
已知中序遍历序列和另外一个序列可以求第三个序列。
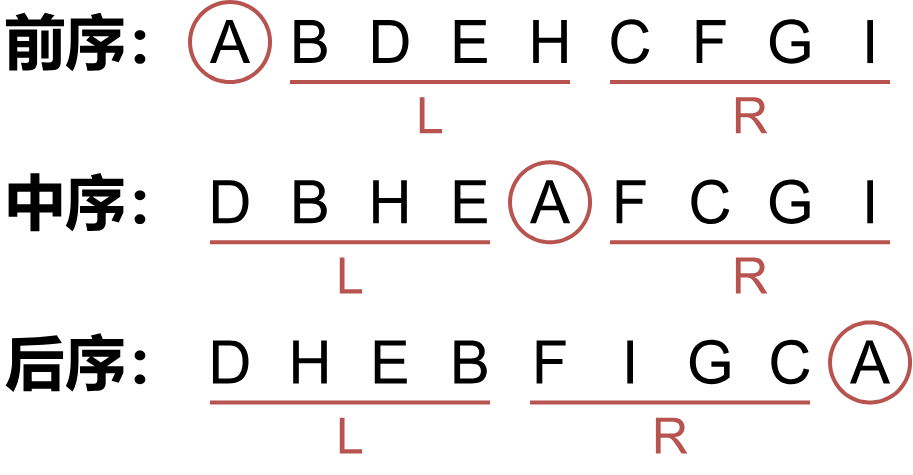
- 前序的第一个是 root,后序的最后一个是 root。
- 先确定根节点,然后根据中序遍历,在根左边的为左子树,根右边的为右子树。
- 对于每一个子树可以看成一个全新的树,仍然遵循上面的规律。
例题:前序+中序还原后序
前序:ABDECFG
中序:DEBACFG
方法:
-
根 = 前序第一个 →
A- 在中序中找到
A,则DEB为左子树,CFG为右子树 - 接下来继续分析左右子树谁是根,谁是左子树,谁是右子树即可。
- 在中序中找到
-
左子树根 = 前序第一个 →
B- 在中序中找到
B,则DE为左子树,无右子树。
- 在中序中找到
- 右子树根 = 前序第一个 →
C- 在中序中找到
C,则无左子树,FG为右子树。
- 在中序中找到
接下来继续确定 DE 和 FG 最后不难得出树的形态如下图所示。
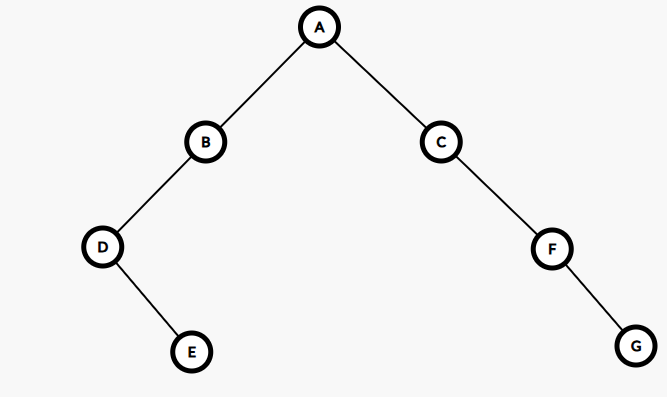
根据后序遍历的规则可以得出该二叉树的后序遍历是:EDBGFCA。
霍夫曼树(Huffman Tree)¶
树的带权路径长度
设二叉树具有 $n$ 个带权叶结点,从根结点到各叶结点的路径长度与相应叶节点权值的乘积之和称为 树的带权路径长度(Weighted Path Length of Tree,WPL)。
设 $w_i$ 为二叉树第 $i$ 个叶结点的权值,$l_i$ 为从根结点到第 $i$ 个叶结点的路径长度,则 WPL 计算公式如下:

如上图所示,其 WPL 计算过程与结果如下:
霍夫曼算法¶
霍夫曼算法用于构造一棵霍夫曼树,算法步骤如下:
- 初始化:由给定的 $n$ 个权值构造 $n$ 棵只有一个根节点的二叉树,得到一个二叉树集合 F。
- 选取与合并:从二叉树集合 F 中选取根节点权值 最小的两棵 二叉树分别作为左右子树构造一棵新的二叉树,这棵新二叉树的根节点的权值为其左、右子树根结点的权值和。
- 删除与加入:从 F 中删除作为左、右子树的两棵二叉树,并将新建立的二叉树加入到 F 中。
- 重复 2、3 步,当集合中只剩下一棵二叉树时,这棵二叉树就是霍夫曼树。

霍夫曼编码的含义¶
在进行程序设计时,通常给每一个字符标记一个单独的代码来表示一组字符,即 编码。
在进行二进制编码时,假设所有的代码都等长,那么表示 $n$ 个不同的字符需要 $\left \lceil \log_2 n \right \rceil$ 位,称为 等长编码。
如果每个字符的 使用频率相等,那么等长编码无疑是空间效率最高的编码方法,而如果字符出现的频率不同,则可以让频率高的字符采用尽可能短的编码,频率低的字符采用尽可能长的编码,来构造出一种 不等长编码,从而获得更好的空间效率。
在设计不等长编码时,要考虑解码的唯一性,如果一组编码中任一编码都不是其他任何一个编码的前缀,那么称这组编码为 前缀编码,其保证了编码被解码时的唯一性。
霍夫曼树可用于构造 最短的前缀编码,即 霍夫曼编码(Huffman Code),其构造步骤如下:
- 设需要编码的字符集为:$d_1,d_2,\dots,d_n$,他们在字符串中出现的频率为:$w_1,w_2,\dots,w_n$。
- 以 $d_1,d_2,\dots,d_n$ 作为叶结点,$w_1,w_2,\dots,w_n$ 作为叶结点的权值,构造一棵霍夫曼树。
- 规定哈夫曼编码树的左分支代表 $0$,右分支代表 $1$,则从根结点到每个叶结点所经过的路径组成的 $0、1$ 序列即为该叶结点对应字符的编码。

例题:
字符:a,b,c,d,e,f
频率:5%, 9%, 12%, 13%, 16%, 45%
步骤:
- 取最小两个:
a = 5%,b = 9%→ 合并为14% - 剩余频率:
12%, 13%, 14%, 16%, 45% - 取最小两个:
12%, 13%→25% - 取最小两个:
14%, 16%→30% - 合并
25% + 30%→55% - 最后合并
45% + 55%→100%
哈夫曼编码(根据路径左 0 右 1):
a = 1111b = 1110c = 101d = 100e = 110f = 0 ✅
正确选项: 1111, 1110, 101, 100, 110, 0 ✅
篇幅有限,没有画图。请读者自己画图体会霍夫曼树的过程。
初赛考察点¶
- 树的基本定义。
- 树的一些性质。
- 例如高度为 $5$ 的满二叉树有多少个节点。
- 给定叶子节点数和总节点数算度为 $2$ 的节点数。
- 二叉树的几种遍历方法。
- 还原零一个序列的方法。
- 霍夫曼算法是基于贪心的思想。
- 给定一组字符的出现频率,求每个字符的霍夫曼编码。