最短路
记号¶
为了方便叙述,这里先给出下文将会用到的一些记号的含义。
- $n$ 为图上点的数目,$m$ 为图上边的数目;
- $s$ 为最短路的源点;
- $D(u)$ 为 $s$ 点到 $u$ 点的 实际 最短路长度;
- $dis(u)$ 为 $s$ 点到 $u$ 点的 估计 最短路长度。任何时候都有 $dis(u) \geq D(u)$。
- 特别地,当最短路算法终止时,应有 $dis(u)=D(u)$。
- $w(u,v)$ 为 $(u,v)$ 这一条边的边权。
性质¶
对于边权为正的图,任意两个结点之间的最短路:
-
不会经过重复的结点。
-
不会经过重复的边。
-
任意一条的结点数不会超过 $n$,边数不会超过 $n-1$。
Bellman-Ford 算法¶
Bellman–Ford 是一种单源最短路径算法:
- 可处理图中存在负边权的情况
- 可用于检测 负权环
- 时间复杂度:$\mathcal{O}(nm)$
使用 直接存边法 实现,算法核心是反复对每条边进行 松弛操作(Relaxation)
松弛操作¶
对于一条边 $(u, v, w)$,松弛操作的定义为:
含义:尝试通过 $u \to v$ 这条边更新 $v$ 的最短路径值。
如果通过 $u$ 到达 $v$ 的路径更短,则更新 $dis[v]$。
算法流程¶
- 初始化 $dis[s] = 0$,其余 $dis[i] = \infty$
- 重复 $n-1$ 次:
- 对每条边 $(u, v, w)$ 执行松弛操作
每轮松弛都是 $\mathcal{O}(m)$,共 $n-1$ 轮,时间复杂度为 $\mathcal{O}(nm)$。
为何只需 $n-1$ 轮松弛?
定理:从源点 $s$ 到图中任意一点 $v$ 的最短路径,最多只包含 $n-1$ 条边。
Bellman-Ford 算法每一轮最多将一条最短路边加入,最多有 $n-1$ 条边组成最短路,所以只需松弛 $n-1$ 轮。
代码实现
struct Edge
{
int u, v, w;
} e[M]; // M 表示边的上限
void bellman_ford(int s)
{
for (int i = 1; i <= n; i++) dis[i] = 1e9;
dis[s] = 0;
for (int t = 1; t < n; t++) // 没有负边权,松弛 n - 1 次即可
{
for (int i = 1; i <= m; i++)
{
int u = e[i].u, v = e[i].v, w = e[i].w;
if (dis[u] == 1e9) // 避免假松弛
{
continue;
}
if (dis[v] > dis[u] + w) // 判断是否会进行松弛
{
dis[v] = dis[u] + w;
}
}
}
}
总结¶
- Bellman–Ford 是最经典的负权图最短路算法。
- 重复 $n-1$ 次松弛操作。
- 使用 直接存边法 实现,适合稀疏图。
- 缺点是相对较慢:$\mathcal{O}(nm)$,但稳定可靠。
SPFA 算法¶
SPFA(Shortest Path Faster Algorithm)是对 Bellman–Ford 算法的优化版本。
观察 Bellman–Ford 会发现:实际上很多边的松弛操作是「无效的」。我们希望:
- 只有那些最近「刚刚被更新」的点的出边才可能引起下一次松弛
- 用一个队列维护「当前可能引发松弛的点」,避免无谓地遍历所有边
这就是 SPFA 算法的核心思想。
核心思想¶
只需要处理那些「刚刚被更新过」的点。我们用一个队列维护这些点,过程如下:
- 初始将源点 $s$ 加入队列;
- 每次从队首取出一个点 $u$,尝试用它松弛所有出边;
- 若某个点 $v$ 的 $dis[v]$ 被更新,并且 $v$ 不在队列中,则将其加入队列。
算法流程¶
- 初始化所有点的 $dis = \infty$,源点 $dis[s] = 0$;
- 初始化队列,将 $s$ 加入队列,并设置 $vis[s] = 1$ 表示 $s$ 当前在队列中;
- 当队列不空时:
- 取出队首元素 $u$,设置 $vis[u] = 0$(出队);
- 遍历 $u$ 所有出边 $(u,v,w)$:
- 若 $dis[v] > dis[u] + w$,进行松弛;
- 若 $v$ 不在队列中,则将 $v$ 入队,并设置 $vis[v] = 1$。
其余注意事项
- 队列判重方式:使用 $vis$ 数组记录某个点是否在队列中,而不是是否已访问过;
- 图的存储方式:SPFA 只需访问一个点的出边,建议使用「邻接表」;
- 复杂度分析:
- 最好情况接近 $O(m)$;
- 最坏情况可退化为 $O(nm)$(例如存在负环或近似负环结构);
代码
#include <bits/stdc++.h>
using namespace std;
const int N = 1e4 + 5;
int dis[N], vis[N], n, m, s;
vector<pair<int, int>> e[N];
void spfa(int s)
{
for (int i = 1; i <= n; i++) dis[i] = INT_MAX;
dis[s] = 0;
vis[s] = 1;
queue<int> q;
q.push(s);
while (!q.empty())
{
int u = q.front();
q.pop();
vis[u] = 0;
for (auto it : e[u])
{
int v = it.first, w = it.second;
if (dis[v] > dis[u] + w)
{
dis[v] = dis[u] + w;
if (!vis[v])
{
vis[v] = 1;
q.push(v);
}
}
}
}
}
int main()
{
cin >> n >> m >> s;
for (int i = 1; i <= m; i++)
{
int u, v, w;
cin >> u >> v >> w;
e[u].push_back({v, w});
}
spfa(s);
for (int i = 1; i <= n; i++) cout << dis[i] << " ";
return 0;
}
总结¶
- SPFA 是 Bellman–Ford 的「按需松弛」优化版本;
- 使用队列维护“可能发生松弛”的点,大大减少不必要计算;
- 一般运行效率远优于 Bellman–Ford,但最坏复杂度仍为 $O(nm)$;
- 适合稀疏图,代码实现简洁,实际效果优秀;
Dijkstra 算法¶
Dijkstra 算法由荷兰计算机科学家 E. W. Dijkstra 于 1956 年提出,1959 年公开发表。
它用于求解 边权非负的图 中,单源最短路径 问题,是经典的贪心策略代表。
核心思想¶
将所有点分为两类:
- $S$ 集合:最短路已经确定的点;
- $T$ 集合:最短路未确定的点;
初始时所有点属于 $T$ 集合,$dis(s) = 0$,其余点 $dis = +\infty$。每次从 $T$ 中选取当前 $dis$ 最小的点加入 $S$,并用它去松弛其它点,直到 $T$ 为空。
伪代码流程
每次迭代找出 $T$ 中 $dis$ 最小的点 $u$,将其加入 $S$,并对 $u$ 的邻点尝试松弛。最多迭代 $n$ 次即可求出最短路。
for (迭代 n 次)
{
找到一个 T 集合内 dis 最小的点记为 u
将 u 加入 S 集合,代表 u 的最短路已确定
for (遍历其余所有点)
{
执行松弛操作
}
}
正确性证明(反证法)¶
设当前从 $T$ 中选出 $dis$ 最小的点 $v$,假设存在从源点 $s$ 到 $v$ 的更短路径,且这条路径需经过 $T$ 集合内的某个 $y$ 点。
根据假设,应有 $dis_y + w_{y\to v} < dis_v$,由于边权非负,因此推出 $dis_y < dis_v$ 与 $v$ 是 $T$ 集合中最小的点矛盾。
结论: 当前选出的点 $v$ 的 $dis$ 值即为最短路长度。
实现流程¶
为了实现 Dijkstra 算法的暴力版(邻接矩阵 + 朴素贪心),我们遵循以下步骤:
- 使用布尔数组 $vis[i]$ 表示点 $i$ 是否已加入 $S$ 集合,初始全为 $\texttt{false}$。
- 初始化距离数组 $dis$:$dis[s] = 0$,其余点设为 $+\infty$,表示起点到各点的初始距离。
- 重复以下操作 $n$ 次:
- 在所有未加入 $S$ 的点中(即 $vis[i] = \texttt{false}$),找到具有最小 $dis$ 值的点 $u$;
- 标记 $vis[u] = \texttt{true}$,表示 $u$ 已加入 $S$ 集合;
- 遍历 $u$ 的所有邻点 $v$,若 $dis[v] > dis[u] + w(u,v)$,则执行松弛操作:$dis[v] = dis[u] + w(u,v)$。
-
最终,$dis[i]$ 存储了从源点 $s$ 到每个点 $i$ 的最短路径长度。
-
时间复杂度 $O(n^2)$,适合稠密图。
邻接矩阵写法
#include <bits/stdc++.h>
using namespace std;
const int N = 1e3 + 5;
long long dis[N], vis[N], n, m, s;
int g[N][N];
void dijkstra(int s)
{
for (int i = 1; i <= n; i++) dis[i] = 1e18;
dis[s] = 0;
for (int t = 1; t <= n; t++)
{
int u = -1;
for (int i = 1; i <= n; i++)
{
if (!vis[i]) // 点 i 属于 T 集合
{
if (u == -1) u = i;
else if (dis[i] < dis[u]) u = i;
}
}
vis[u] = 1; // 点 u 加入 S 集合,最短路确定
for (int v = 1; v <= n; v++)
{
if (dis[v] > dis[u] + g[u][v])
{
dis[v] = dis[u] + g[u][v];
}
}
}
}
int main()
{
ios::sync_with_stdio(false);
cin.tie(0);
cin >> n >> m >> s;
memset(g, 0x3f , sizeof(g));
for (int i = 1; i <= m; i++)
{
int u, v, w;
cin >> u >> v >> w;
g[u][v] = min(g[u][v], w);
}
dijkstra(s);
for (int i = 1; i <= n; i++)
{
if (dis[i] == 1e18) dis[i] = -1;
cout << dis[i] << " ";
}
return 0;
}
邻接表写法
for (int i = 1; i <= n; i++) dis[i] = 1e18;
dis[s] = 0;
for (int i = 1; i <= n; i++) // 迭代 n 次
{
int u = -1; // 每次取出 T 集合距离最小的点 u 初始化为 -1
for (int v = 1; v <= n; v++)
{
if (!vis[v]) // v 未加入集合 S
{
if (u == -1 || dis[v] < dis[u]) // 找一个距离最小的点存到 u
{
u = v;
}
}
}
vis[u] = 1; // u 加入集合 S
for (auto it : e[u])
{
int v = it.first, w = it.second;
if (dis[v] > dis[u] + w)
{
dis[v] = dis[u] + w;
}
}
}
负边权会出错的例子¶
考虑下图,尝试使用 Dijkstra 算法从 $1$ 出发计算最短路。
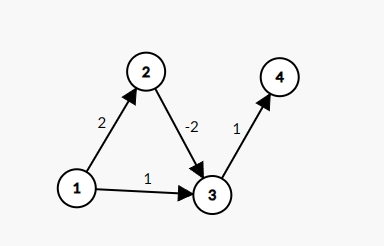
Dijkstra 求得:
实际最短路径为:$dis_4 = 1$。错误的原因在于负边未被正确处理。
总结¶
- Dijkstra 是基于贪心的,每次选择当前 $dis$ 最小的点进行松弛;
- 它不回溯、不修正,不能处理负边的情况;
- 对于稠密图使用邻接矩阵,复杂度为 $O(n^2)$,适合点数不多但边很多的情况;
- 重边情况下仅保留最小边;
堆优化 Dijkstra¶
在朴素 Dijkstra 中,每次迭代都需在 $T$ 集合中寻找 $dis$ 最小的点,耗时 $O(n)$,整体复杂度 $O(n^2)$。
若能使用一个数据结构,支持:
- 动态插入点
- 快速获取当前 $dis$ 最小的点
则能将寻找最小值的过程加速,降低整体时间复杂度。最常用的数据结构是:小根堆 即优先队列。
实现准备¶
由于这里需要记录距离以及编号,因此用 pair<int, int> 作为元素类型实现优先队列。
-
将距离放入 $\texttt{first}$,编号放入 $\texttt{second}$ 即可。
-
使用
array<int, 2>同理。
#define pii pair<int, int> // 根据数据范围决定 first 类型
priority_queue<pii, vector<pii>, greater<pii>> q; // 小根堆
#define ary array<int, 2> // 根据数据范围决定 first 类型
priority_queue<ary, vector<ary>, greater<ary>> q; // 小根堆
流程¶
- 初始化:$dis[i] = +\infty, \; dis[s] = 0$,将起点入队。
- 当优先队列不为空:
- 弹出队头节点 $u$,若 $u$ 已处在 $S$ 集合,则跳过。
- 否则,将 $u$ 标记为访问代表加入 $S$ 集合,并尝试更新所有邻点 $v$。
- 若成功松弛 $v$,将其入队。
- 使用小根堆优化后,Dijkstra 的时间复杂度变为 $O(m \log m)$,适合稀疏图。
代码¶
#include <bits/stdc++.h>
#define pii pair<int, int>
using namespace std;
const int N = 1e5 + 5;
int dis[N], n, m, s;
vector<pii> e[N];
bool vis[N];
void dijkstra(int s)
{
for (int i = 1; i <= n; i++) dis[i] = 1e9;
dis[s] = 0;
priority_queue<pii, vector<pii>, greater<pii>> q;
q.push({dis[s], s});
while (!q.empty())
{
auto now = q.top();
q.pop();
int u = now.second;
if (vis[u]) continue; // 已经加入 S 集合就跳过了
vis[u] = 1;
for (auto it : e[u])
{
int v = it.first, w = it.second;
if (dis[v] > dis[u] + w)
{
dis[v] = dis[u] + w;
q.push({dis[v], v});
}
}
}
}
int main()
{
ios::sync_with_stdio(false);
cin.tie(0);
cin >> n >> m >> s;
for (int i = 1; i <= m; i++)
{
int u, v, w;
cin >> u >> v >> w;
e[u].push_back({v, w});
}
dijkstra(s);
for (int i = 1; i <= n; i++)
{
cout << dis[i] << " ";
}
return 0;
}
总结对比¶
Dijkstra 是用于 非负边权图 的单源最短路算法:
暴力版本:
- 时间复杂度:$O(n^2)$
- 适合稠密图
堆优化版本:
- 时间复杂度:$O(m\log n)$
- 适合稀疏图
两种方法都要求掌握,稠密图上使用暴力有的时候快于堆优化。
Floyd 算法¶
Floyd 算法是一种经典的 多源最短路径 算法,能在任意(有向/无向、正/负权)图上求出所有点对之间的最短路。
唯一要求:图中不能存在负权环,否则最短路长度不存在。
核心思想¶
基于动态规划,将 允许经过的中间点 编号视为维度,定义状态:
即 $x\to y$ 的路径经过的点的编号必须是 $\le k$ 的。
最终答案:$f_{n}[x][y]$,即允许任意中间点时的最短路。
状态转移
考察是否使用编号为 $k$ 的中间点来中转:
解释
考虑任意两点 $x$ 和 $y$:
取两者的最小值,即是 最多用到编号 $\le k$ 的任意节点 的最短路。
初始化
初始时不允许经过任何中间点,自身与邻接关系决定距离:
存图方式:邻接矩阵最直观。
代码实现¶
时间 和 空间复杂度:$O(n^3)$。
// f[k][x][y]: 只允许中间点编号≤k
for (int k = 1; k <= n; ++k)
for (int x = 1; x <= n; ++x)
for (int y = 1; y <= n; ++y)
f[k][x][y] = min(f[k - 1][x][y], f[k - 1][x][k] + f[k - 1][k][y]);
降维优化
原三维更新:
由于无负环时一定有 $f_{k-1}[k][k]=0$,可证明:
这样,读写不会冲突,可直接用
在二维表上原地更新,节省一维空间。
// 初始化
for (int x = 1; x <= n; x++)
for (int y = 1; y <= n; y++)
if (x != y) f[x][y] = 1e9;
while (m--)
{
int u, v, w;
cin >> u >> v >> w;
// 取 min 是防止重边,重边保留最短的即可
f[u][v] = min(f[u][v], w);
// 无向图添加:f[v][u] = min(f[v][u], w);
}
for (int k = 1; k <= n; ++k)
for (int x = 1; x <= n; ++x)
for (int y = 1; y <= n; ++y)
f[x][y] = min(f[x][y], f[x][k] + f[k][y]);
总结¶
-
循环的顺序:外层 枚举中间点 $k$,内层 枚举所有点对 $(x,y)$。
-
适用场景:全图任意两点查询、图较小($n\lesssim500$)。
- 不能处理负环——若有负环,不存在最短路。
- 存图方式选择邻接矩阵。
最短路算法总结(不区分图有向还是无向)¶
| 算法名字 | 时间复杂度 | 空间复杂度 | 类型 | 负权图是否适用 | 适用的图 |
|---|---|---|---|---|---|
| bellman-ford | $O(nm)$ | $O(m)$ | 单源 | 适用 | 少部分图 |
| spfa | 最坏 $O(nm)$ | $O(m)$ | 单源 | 适用 | 稀疏图 |
| dijsktra(暴力) | $O(n^2)$ | $O(m)$ | 单源 | 不适用 | 稠密图 |
| dijkstra(堆优化) | $O(m\log m)$ | $O(m)$ | 单源 | 不适用 | 稀疏图 |
| floyd | $O(n^3)$ | $O(n^2)$ | 多源 | 适用 | 稠密图 |