🌲 树基础¶
🎯 引入¶
图论中的树和现实生活中的树长得一样,只不过我们习惯于处理问题的时候把树根放到上方来考虑。这种数据结构看起来像是一个倒挂的树,因此得名。
📌 定义¶
一个没有固定根结点的树称为 无根树(unrooted tree)。无根树有几种等价的形式化定义:
有 $n$ 个结点,$n-1$ 条边的连通无向图
-
无向无环的连通图
-
任意两个结点之间有且仅有一条简单路径的无向图
-
任何边均为桥的连通图
-
没有圈,且在任意不同两点间添加一条边之后所得图含唯一的一个圈的图
在无根树的基础上,指定一个结点称为 根,则形成一棵 有根树(rooted tree)。有根树在很多时候仍以无向图表示,只是规定了结点之间的上下级关系,详见下文。
🌿 有关树的定义¶
✅ 适用于无根树和有根树¶
| 概念 | 说明 |
|---|---|
| 🌲 森林(forest) | 每个连通分量(连通块)都是树的图 |
| 🌿 生成树(spanning tree) | 一个连通无向图的生成子图,要求是树 |
| 🍃 叶结点(leaf node) | 对于无根树是度数 $\le 1$;有根树是没有子结点的节点 |
💡 为什么不是度数恰为 $1$?考虑 $n = 1$。
🔒 只适用于有根树¶
| 概念 | 说明 |
|---|---|
| 👨👧 父亲(parent) | 除根以外每个节点,从该节点到根路径上的第二个节点 |
| 🧓 祖先(ancestor) | 从该节点到根的路径上的节点(不含自身) |
| 👶 子结点(child) | 若 $u$ 是 $v$ 的父,则 $v$ 是 $u$ 的子 |
| 📏 深度(depth) | 到根的路径上的边数 |
| 🗻 高度(height) | 所有结点深度的最大值 |
| 🤝 兄弟(sibling) | 同一父结点下的多个子节点 |
| 🧬 后代(descendant) | 子节点及其后代 |
| 🌳 子树(subtree) | 删掉与父相连的边后该结点所在的子图 |

子树示意图:

⭐ 特殊的树¶
| 类型 | 描述 |
|---|---|
| 📏 链(chain) | 每个结点的度数不超过 2 |
| 🌼 菊花/星星(star) | 存在 $u$,所有其他节点都与 $u$ 相连 |
| 🌲 有根二叉树 | 每个节点最多两个子结点 |
| 🌳 完整二叉树 | 每个节点要么没有子节点要么有两个 |
| 🧱 完全二叉树 | 只有最后两层可不满,最底层集中左侧 |
| 🏠 完美二叉树(满二叉树) | 所有叶节点深度相同,非叶节点都有两个子节点 |
- 🌳 完整二叉树(full/proper binary tree):每个节点要么没有子节点要么有两个

- 🧱 完全二叉树(complete binary tree):只有最下面两层结点的度数可以小于 $2$,且最下面一层的结点都集中在该层最左边的连续位置上。

- 🏠 完美二叉树(满二叉树)(perfect binary tree):所有叶结点的深度均相同,且所有非叶节点的子节点数量均为 2 的二叉树称为完美二叉树。
- 「满二叉树」多指完美二叉树。

💾 存储方式¶
🧭 只记录父节点¶
用一个数组 parent[N] 记录每个结点的父亲结点。
这种方式可以获得的信息较少,不便于进行自顶向下的遍历。常用于自底向上的递推问题中。
🔗 邻接表¶
- 对于无根树:为每个结点开辟一个线性列表,记录所有与之相连的结点。
vector<int> adj[N];
for (int i = 1; i < n; i++) // 树是 n - 1 条边
{
int u, v;
cin >> u >> v;
adj[u].push_back(v);
adj[v].push_back(u);
}
- 对于有根树:
- 方法一:若给定的是无向图,则仍可以上述形式存储。下文将介绍如何区分结点的上下关系。
- 方法二:若输入数据能够确保结点的上下关系,则可以利用这个信息。为每个结点开辟一个线性列表,记录其所有子结点;若有需要,还可在另一个数组中记录其父结点。
vector<int> adj[N];
for (int i = 1; i < n; i++) // 树是 n - 1 条边
{
int u, v;
cin >> u >> v; // 如果明确表示 u 是 v 的父则
// parent[v] = u; 如果表示 v 是 u 的儿子则可以记录
adj[u].push_back(v);
// adj[v].push_back(u); 没有明确表示需要此句
}
- 当然也可以用链式前向星实现。
🌿 二叉树¶
需要记录每个结点的左右子结点。
int parent[N];
int lson[N], rson[N]; // 开两个数组记录每个节点的左右儿子是谁
🔍 遍历¶
🌐 树上 DFS¶
在树上 DFS 是这样的一个过程:先访问根节点,然后分别访问根节点每个儿子的子树。
可以用来求出每个节点的深度、父亲等信息。
二叉树 DFS 遍历¶
由于二叉树最多只有两个子节点,在存储时记录左右儿子编号。根据遍历左右儿子的访问顺序不同,通常分为以下三种遍历方式。
先序遍历¶
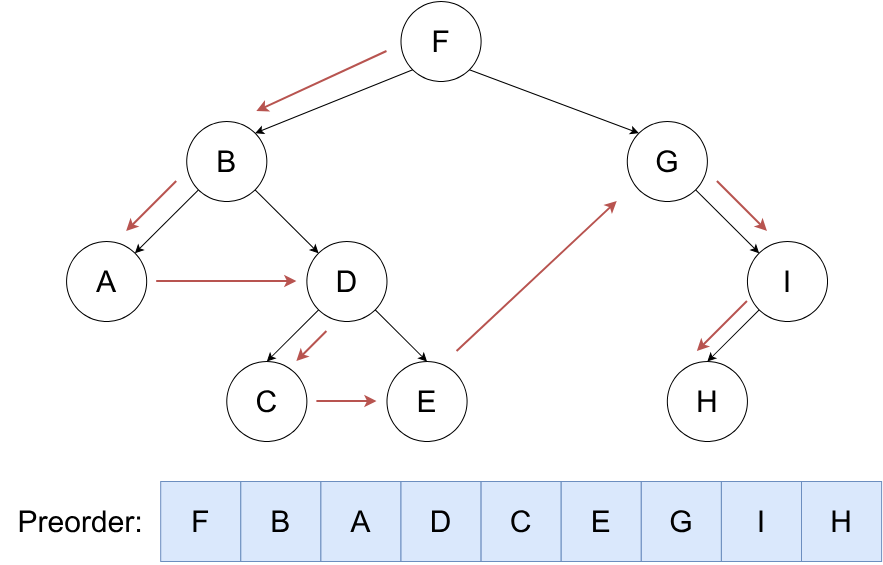
按照 根,左,右 的顺序遍历二叉树。
void dfs(int u)
{
cout << u << " ";
if (lson[u]) dfs(lson[u]);
if (rson[u]) dfs(rson[u]);
}
中序遍历¶
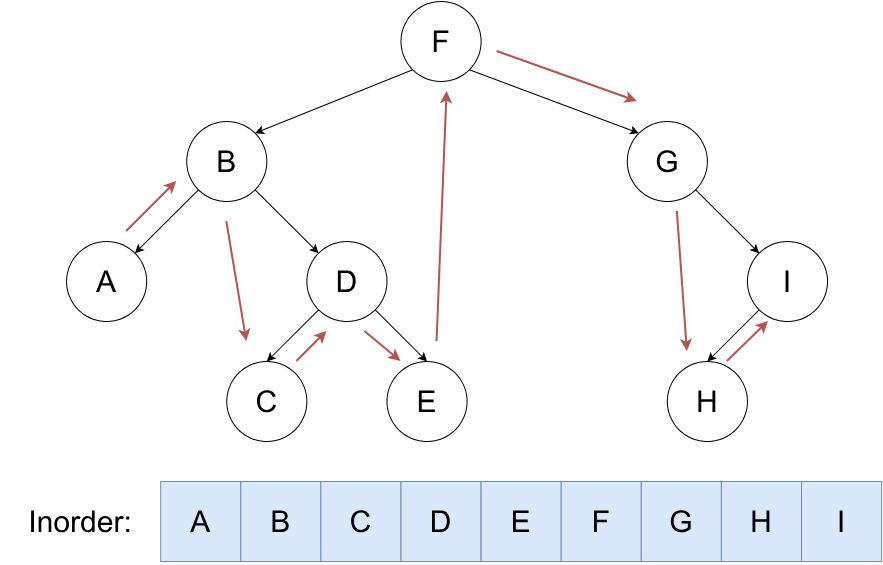
按照 左,根,右 的顺序遍历二叉树。
void dfs(int u)
{
if (lson[u]) dfs(lson[u]);
cout << u << " ";
if (rson[u]) dfs(rson[u]);
}
后序遍历¶
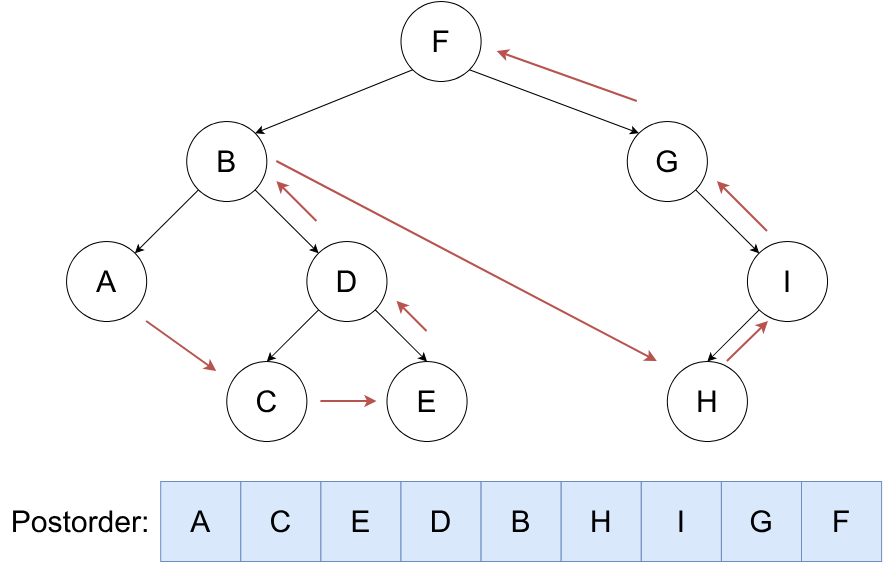
按照 ,右,根 的顺序遍历二叉树。
void dfs(int u)
{
if (lson[u]) dfs(lson[u]);
if (rson[u]) dfs(rson[u]);
cout << u << " ";
}
🔁 总结¶
| 遍历 | 顺序 | 代码 |
|---|---|---|
| 前序 | 根 → 左 → 右 | cout → dfs(l) → dfs(r) |
| 中序 | 左 → 根 → 右 | dfs(l) → cout → dfs(r) |
| 后序 | 左 → 右 → 根 | dfs(l) → dfs(r) → cout |
反推¶
已知中序遍历序列和另外一个序列可以求第三个序列。
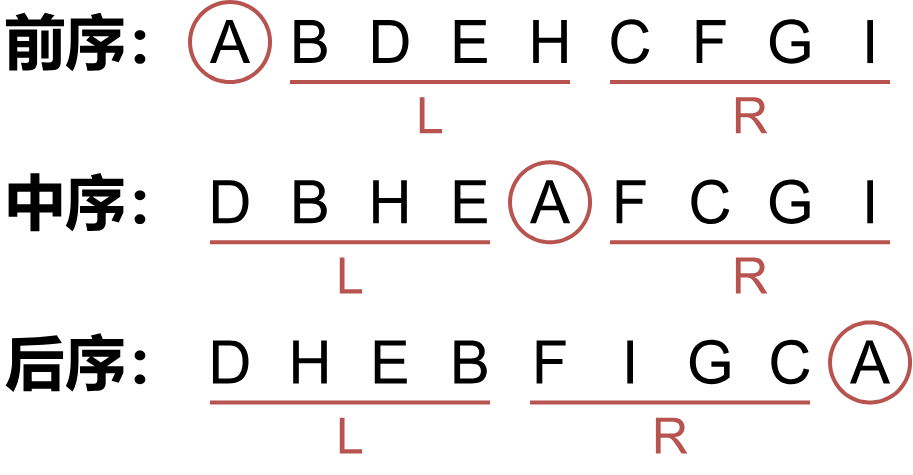
- 前序的第一个是 root,后序的最后一个是 root。
- 先确定根节点,然后根据中序遍历,在根左边的为左子树,根右边的为右子树。
- 对于每一个子树可以看成一个全新的树,仍然遵循上面的规律。
下面给出中序+后序推前序的代码
例题:[NOIP2001 普及组] 求先序排列
#include <bits/stdc++.h>
using namespace std;
const int N = 1e3 + 5;
string s, t;
void dfs(string s, string t) // s 是后序,t 是中序
{
if (!s.size()) return ;
// 子树的根
int pos = t.find(s[s.size() - 1]);
cout << t[pos];
dfs(s.substr(0, pos), t.substr(0, pos));
dfs(s.substr(pos, t.size() - pos - 1), t.substr(pos + 1));
}
int main()
{
cin >> t >> s;
dfs(s, t);
return 0;
}
📥 树上 BFS¶
从树根开始,严格按照层次来访问节点。
BFS 过程中也可以顺便求出各个节点的深度和父亲节点。
树的层序遍历¶
树层序遍历是指按照从根节点到叶子节点的层次关系,一层一层的横向遍历各个节点。根据 BFS 的定义可以知道,BFS 所得到的遍历顺序就是一种层序遍历。但层序遍历要求将不同的层次区分开来,所以其结果通常以二维数组的形式表示。
例如,下图的树的层序遍历的结果是 [[1], [2, 3, 4], [5, 6]](每一层从左向右)。

void bfs(int root)
{
queue<int> q;
q.push(root);
vis[root] = 1;
while (!q.empty())
{
int u = q.front();
q.pop();
for (auto v : e[u])
{
if (!vis[v])
{
q.push(v);
vis[v] = 1;
}
}
}
}
🧭 无根树 DFS¶
过程¶
树的遍历一般为深度优先遍历,这个过程中最需要注意的是避免重复访问结点。
由于树是无环图,因此只需记录当前结点是由哪个结点访问而来,此后进入除该结点外的所有相邻结点,即可避免重复访问。
void dfs(int u, int fa)
{
cout << u << " ";
for (auto v : e[u])
{
if (v == fa) // 说明是父节点,必须跳过。
{
continue;
}
dfs(v, u);
}
}
int main()
{
cin >> n;
for (int i = 1; i < n; i++)
{
int u, v;
cin >> u >> v;
e[u].push_back(v);
e[v].push_back(u);
}
dfs(1, 0); // 无根树根随便指定
}
🛠️ 常见应用¶
🧩 节点深度¶
定义 $depth[u]$ 为节点 $u$ 的深度,则 $depth[u] = depth[fa[u]] + 1$。
- 解释:$u$ 的深度在父亲 $fa$ 的深度的基础上加 $1$
void dfs(int u, int fa)
{
depth[u] = depth[fa] + 1;
for (int v : e[u])
{
if (v != fa)
{
dfs(v, u);
}
}
}
📦 子树大小¶
定义 $size[u]$ 为节点 $u$ 的子树大小,则 $size[u] = \sum_{v \in G[u]} size[v] + 1$。
- 解释:$u$ 的子树大小是 $u$ 的所有子节点的子树大小之和加上 $1$。
- 需要在回溯时更新子树大小。
void dfs(int u, int fa)
{
size[u] = 1;
for (int v : e[u])
{
if (v != fa)
{
dfs(v, u);
size[u] += size[v];
}
}
}
🧮 每层节点数¶
- 定义
cnt[i]为第i层节点的个数,cnt[i]的初始值为0。 - 定义
vector<int> a[N]存储每一层的节点编号。
void dfs(int u, int fa)
{
depth[u] = depth[fa] + 1;
cnt[depth[u]]++;
a[depth[u]].push_back(u);
for (auto v : e[u])
{
if (v != fa)
{
dfs(v, u);
}
}
}
🧾 总结¶
- 树是无环连通图,结构简单但信息丰富
- 有根树可定义深度、子树等层级关系
- 遍历可使用 DFS(含前中后序)与 BFS(层序)
- 存储方式灵活,依据用途选择合适结构