并查集
📘 引入¶
并查集是一种用于管理元素所属集合的数据结构,实现为一棵森林,其中每棵树表示一个集合,🌲树中的节点表示对应集合中的元素。
并查集支持两种操作:
-
🔗 合并(Union):合并两个元素所属集合 🧩
-
🔍 查询(Find):查询某个元素所属集合 🔎
这种结构在图论🗺️、集合操作🧮等应用中非常高效⚡,尤其适用于处理连通性问题🌐。
并查集在经过修改后可以支持单个元素的删除、移动;使用动态开点线段树还可以实现可持久化并查集。
🧠 基本思想¶
并查集通过「父节点」的方式表示集合中的关系,每个元素初始时是自己的父节点 👤。通过一系列合并操作,将不同元素连接在一起。
⚙️ 操作详解¶
🔧 初始化¶
初始时,每个元素都位于一个单独的集合,表示为一棵只有根节点的树。方便起见,我们将根节点的父亲设为自己 👤。
for (int i = 1; i <= n; i++)
{
fa[i] = i; // 每个元素的祖先为其自身 👤
}
🔍 查询¶
我们需要沿着树向上移动,直至找到根节点 🌲。

实现方式:
- 📌 递归调用直到找到根节点:
int find(int x)
{
if (fa[x] == x) return x; // 自己是这个集合的祖先 👑
return find(fa[x]); // 递归查找父亲 🔁
}
- 🔁 使用
while循环逐步向上查找,直至找到根节点:
int find(int x)
{
while (fa[x] != x)
{
x = fa[x]; // 逐步向上查找父节点 🧗
}
return x; // 返回根节点 🎯
}
⏱️ 复杂度分析
- 在最坏情况下,无论使用递归还是
while循环,查询操作的时间复杂度为 $O(n)$ 🐌。 - 这是因为每次查询时,只能向上移动一格。如果集合呈现出一条链状结构,那么查找祖先节点的过程需要 $O(n)$ 的时间,这对于大规模数据来说是不可接受的 🚫。
🚀 路径压缩¶
路径压缩是一种优化技巧,具体优化方式为在查询过程中经过的每个元素都属于该集合,将其直接连到根节点以加快后续查询 🏎️。如下图示:

路径压缩后,查询祖先的时间复杂度为 $O(\log(n))$ ⏱️➡️⚡。
- 📌 递归实现:
int find(int x)
{
if (fa[x] == x) return x;
return fa[x] = find(fa[x]); // 路径压缩 🧬
}
- 🔁
while循环实现:
int find(int x)
{
while (fa[x] != x)
{
fa[x] = fa[fa[x]]; // 跳过一层父节点 🕳️
x = fa[x];
}
return x; // 返回根节点 🎯
}
🔗 合并¶
要合并两棵树,只需要将一棵树的根节点连到另一棵树的根节点 🌳➡️🌲。如下图所示:

🧩 代码实现:
首先找到两个集合的祖先节点编号,然后直接相连即可 🧶。时间复杂度为 $O(\log(n))$ ⏱️。
void merge(int x, int y)
{
x = find(x), y = find(y);
if (x == y) return ;
fa[x] = y; // x 所在树挂到 y 上 🪢
}
🛠️ 常见应用¶
- 🔗 维护连通性:解决图中的连通性问题,例如判断两个节点是否属于同一连通分量 🌐。
- 🔄 处理集合间的关系:维护集合之间的合并、查询操作,并支持集合大小等附加属性的管理 📏。
- 🧮 图论中的 Kruskal 算法:在求最小生成树时使用并查集来判断是否形成环路 🔁,帮助高效地完成合并操作 ✅。
📏 维护集合大小¶
- 🧱 初始化:使用一个 $sz$ 数组来维护每个集合的大小,初始化时 $sz[i] = 1$,表示每个集合初始时只有自己:
for (int i = 1; i <= n; i++)
{
fa[i] = i, sz[i] = 1; // 初始化,每个集合初始大小为 1 👤
}
- 🔗 合并操作:在执行合并操作时,同步更新新的集合的大小 📈。
void merge(int x, int y)
{
x = find(x), y = find(y);
if (x == y) return;
fa[x] = y; // 合并集合 🌐
sz[y] += sz[x]; // 更新集合大小 🧮
}
🎯 启发式合并¶
启发式合并是一种常用的优化策略。在合并两个集合时,将较小的集合合并到较大的集合中 🪙➡️💰,以减少树的高度,优化查询操作。
这样可以使得合并过程的时间复杂度最小化,有助于后续的查询操作 📉。
void merge(int x, int y)
{
x = find(x), y = find(y);
if (x == y) return;
if (sz[x] > sz[y]) swap(x, y); // 保证 x 为小树 🔁
fa[x] = y; // 小树连向大树 🌱➡️🌳
sz[y] += sz[x]; // 大树大小更新 📈
}
⏱️ 时间复杂度¶
同时使用路径压缩和启发式合并之后,并查集的每个操作平均时间仅为 $O(\alpha(n))$ 🧮,其中 $\alpha$ 为阿克曼函数的反函数,其增长极其缓慢 🐢,也就是说其单次操作的平均运行时间可以认为是一个很小的常数 ⚡。
经典例题: 🌾 USACO16OPEN - Closing the Farm G¶
📘 题目描述
给定一个 无向图 表示农场之间的道路连接,以及一个关闭 $n$ 个农场的顺序。 每次关闭第 $i$ 个农场后,开着的所有农场 是否仍然在同一个连通块中?
📊 数据范围
- 农场数量:$1 \leq n \leq 10^5$
- 道路数量:$1 \leq m \leq 10^5$
💡 解题思路:反向开启,等价模拟
关闭操作不好处理,不如 倒过来 ——我们将问题变为 倒序开启农场!
🔁 倒序处理的优势:
- 每当开启一个农场
u- 将与其相连且已经开启的农场
v合并
- 将与其相连且已经开启的农场
- 与正向问题相同效果:
- 原问题是逐步关闭,我们是逐步开启,效果相同
✨ 实现算法
✏️ 基本步骤
- 定义
int broken[N]记录问题给出的关闭顺序 - 倒序遍历
broken数组,每次开启一个农场u:- 将
u标记为已开启 - 遍历
u的所有邻点v: - 如果
v已开启,就合并u和v
- 将
for (int i = n; i >= 1; i--)
{
int u = broken[i];
vis[u] = 1; // 标记 u 已开启
for (auto v : e[u])
{
if (vis[v])
{
if (find(u) != find(v))
{
merge(u, v);
}
}
}
}
🔎 判断是否全部联通
❌ 暴力做法
遍历所有节点,算出已开启且是集合根节点的数量:
int count = 0;
for (int j = 1; j <= n; j++)
{
if (vis[j] && find(j) == j) count++;
}
if (count == 1) return true;
return false;
- 处理 $n$ 次,每次 $O(n)$,综合处理 $O(n^2)$ 时间复杂度
✅ 优化思路
- 如果已开启的 $i$ 个节点经历 $i-1$ 次合并,那就是全部联通
- 维护一个合并次数
num,如果num + i == n,则YES,否则NO
int num = 0;
for (int i = n; i >= 1; i--)
{
int u = broken[i];
vis[u] = 1;
for (auto v : e[u])
{
if (vis[v] && find(u) != find(v))
{
merge(u, v);
num++;
}
}
if (num + i == n) ans[i] = "YES";
else ans[i] = "NO";
}
✨ 这是一道演示 逆向思考 和 DSU 联通判断优
🧮 带权并查集¶
带权并查集是在并查集的基础上维护额外信息,常见应用包括维护集合大小、节点到祖先的距离等。
每个连通块内部是一棵树,因此等价于维护树上节点与根节点的关系,如子树大小、路径距离等。
📘 经典例题:[NOI2002] 银河英雄传说¶
📘 题目描述: 初始有战舰 $1\ldots 30000$ 各自独立。共 $q\ (1\le q\le5\times10^5)$ 操作:
M x y合并战舰 $x,y$ 所在队列C x y若同队,输出两舰之间隔舰数;否则输出 $-1$
✨思路:
将每个集合看作一棵树,维护每个点导祖先的距离:
- 则查询两舰距离: $\bigl|d[x] - d[y]\bigr| - 1$
为维护上述前缀和,引入:
- $sz[r]$:根 $r$ 所在集合的大小(战舰数)
- $fa[r]$:根 $r$ 的父节点
故而在合并 $(x\to y)$ 时,首先需要执行 :
- $d[f_x] = sz[f_y]$:合并时,原根 $f_x$ 前会多出 $sz[f_y]$ 个战舰。
- $f_x$ 为 $x$ 集合祖先,$f_y$ 为 $y$ 集合祖先。
void merge(int x, int y)
{
int fx = find(x), fy = find(y);
if (fx == fy) return;
fa[fx] = fy; // 挂根
d[fx] = sz[fy]; // fx 前多出 sz[fy] 个战舰
sz[fy] += sz[fx];
}
int query(int x, int y)
{
if (find(x) != find(y)) return -1;
return abs(d[x] - d[y]) - 1;
}
初始化:
- 对所有 $1\le i\le30000$:
fa[i]=i, sz[i]=1, d[i]=0
集合的更新问题
- 朴素更新:
合并 $f_x$ 到 $f_y$ 时,遍历整个 $f_x$ 子树:
缺点:每次合并需要 $O(|\text{子树}|)$,最坏 $O(n)$,总复杂度 $O(nq)$。
- 延迟更新:
不在合并时 立即下推 到所有节点,而是 延迟 到后续查询(find)时再更新;
在 find(x) 递归/回溯过程中:
类似 懒标记 思想,用到时再下推,均摊到 $O(\log(n))$。
int find(int x)
{
if (x == fa[x]) return x;
int p = find(fa[x]); // 递归求出根节点 p
// ← 延迟更新:在回溯时,把父亲的偏移累加到自己
d[x] += d[fa[x]];
return fa[x] = p; // 路径压缩
}
- 延迟更新机制:只更新查询路径上的节点,无需触及整棵子树。
- 摊销效率:每个节点被压缩后不会频繁回溯,整体复杂度 $O(\log(n))$。
🎭 种类并查集¶
一般的并查集用于维护具有连通性、传递性的关系,例如「亲戚的亲戚是亲戚」。
但如果我们要维护 「敌人的敌人是朋友」 这种非传递性关系,该怎么办?
- 种类并查集(也称为扩展域并查集)就是为了解决这类问题而设计的。
📘 经典例题:[NOIP2010 提高组] 关押罪犯¶
为了尽可能减少冲突,我们希望 矛盾大的罪犯不被关在同一个监狱里。做法是:
- 将所有矛盾关系按冲突值从大到小排序;
- 尽可能把矛盾大的犯人分开关;
- 如果出现无法分开的情况,输出当前的冲突值。
🔧 如何建模敌对关系?
问题的难点在于:我们 并不知道哪些人必须在一起,而是知道 哪些人不能在一起。
所以我们使用 2 倍大小的并查集。若有 $n$ 个人,则开 $2n$ 个节点:
- 第 $1 \sim n$ 个表示 和我在同一监狱 的集合;
- 第 $n+1 \sim 2n$ 个表示 和我在不同监狱 的集合。
🧠 示意图
- 例如:对编号 $1$ 的人,$1$ 表示 与他在同监狱,$1+n$ 表示 与他在不同监狱。

- 添加敌对关系:$1$ 和 $2$ 是敌人
merge(1, 2 + n)merge(1 + n, 2)
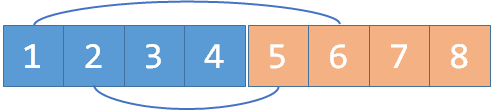
- 继续添加敌对关系:$2$ 和 $4$
观察:$1$ 和 $4$ 间接地成为 朋友 了!敌人的敌人是朋友,这就是种类并查集的核心逻辑。
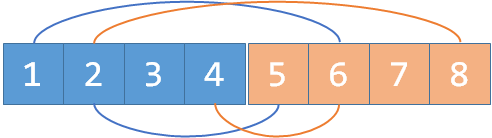
实现流程:
- 按照冲突值从大到小排序;
- 对于每组敌人 $(x, y)$:
- 若
find(x) == find(y):冲突无法避免,输出当前权值; - 否则合并 $(x, y + n)$ 和 $(x+n, y)$;
- 若
- 若全部处理完成无冲突,输出 $0$。
📏 序列上的并查集¶
📘 经典例题:Color the Axis¶
题意: 在一条数轴上有 $n$ 个点,编号为 $1, 2, \ldots, n$。 初始时所有点为黑色。 进行 $m$ 次操作,第 $i$ 次操作将区间 $[l_i, r_i]$ 内的所有点染成白色。 每次操作后,输出剩余黑色点的个数。
数据范围: $1 \le n, m \le 2 \times 10^{5}$
直接模拟的瓶颈
- 如果对每次操作直接枚举区间 $[l_i, r_i]$ 染白,时间复杂度高达 $O(nm)$,无法接受。
- 需要高效跳过已经染白的点,避免重复操作。
- 这时,序列并查集染色法发挥作用。
💡 核心思想
使用并查集维护 每个点右边(包括自己)未染色的位置。
- 令数组 $fa[i]$ 表示第 $i$ 个点当前的「代表」,即从 $i$ 开始往右第一个未染白点的编号。
- 初始时,$fa[i] = i$。
- 染白区间 $[l, r]$ 时,找到 $i = find(l)$:
- 即从 $l$ 右边第一个没有染色的位置开始。
- 如果 $i > r$,说明区间内已无黑点,结束。
- 否则,将点 $i$ 染白,并将 $fa[i]$ 指向 $i+1$,更新 $i$ 右边没有染色的位置与 $i+1$ 右边没有染色的相同。
- 步进 $i = find(i+1)$,继续处理直到 $i > r$。
- 使用序列并查集跳过已经染白的点,避免重复操作。
时间复杂度为 $O((n + m) \alpha(n))$,适合大规模数据。
小细节: 初始化 $fa[n+1]=n+1$。避免无限循环。
#include <bits/stdc++.h>
using namespace std;
const int N = 1.5e5 + 5;
int n, m, fa[N], ans;
int find(int x)
{
return x == fa[x] ? fa[x] : fa[x] = find(fa[x]);
}
void merge(int x, int y)
{
x = find(x), y = find(y);
if (x == y) return ;
fa[x] = y;
}
int main()
{
ios::sync_with_stdio(false), cin.tie(0);
cin >> n >> m;
for (int i = 1; i <= n + 1; i++)
fa[i] = i;
int ans = n;
while (m--)
{
int l, r;
cin >> l >> r;
for (int j = find(l); j <= r; j = find(j + 1))
{
fa[j] = j + 1;
ans--;
}
cout << ans << '\n';
}
return 0;
}