树状数组基础
引入¶
树状数组是一种支持 单点修改 和 区间查询 的,代码量小的数据结构。
假设有这样一道题:
已知一个数列 $a$,你需要进行下面两种操作:
- 给定 $x, y$,将 $a[x]$ 自增 $y$。
- 给定 $l, r$,求解 $a[l \ldots r]$ 的和。
其中第一种操作就是「单点修改」,第二种操作就是「区间查询」。
类似地,还有:「区间修改」、「单点查询」。它们分别的一个例子如下:
- 区间修改:给定 $l, r, x$,将 $a[l \ldots r]$ 中的每个数都分别自增 $x$;
- 单点查询:给定 $x$,求解 $a[x]$ 的值。
注意到,区间问题一般严格强于单点问题,因为对单点的操作相当于对一个长度为 $1$ 的区间操作
普通树状数组维护的信息及运算要满足 结合律 且 可差分,如加法(和)、乘法(积)、异或等。
- 结合律:$(x \circ y) \circ z = x \circ (y \circ z)$,其中 $\circ$ 是一个二元运算符。
- 可差分:具有逆运算的运算,即已知 $x \circ y$ 和 $x$ 可以求出 $y$。
需要注意的是:
- 模意义下的乘法若要可差分,需保证每个数都存在逆元(模数为质数时一定存在);
- 例如 $\gcd$,$\max$ 这些信息不可差分,所以不能用普通树状数组处理。
事实上,树状数组能解决的问题是线段树能解决的问题的子集:树状数组能做的,线段树一定能做;线段树能做的,树状数组不一定可以。然而,树状数组的代码要远比线段树短,时间效率常数也更小,因此仍有学习价值。
有时,在差分数组和辅助数组的帮助下,树状数组还可解决更强的 区间加单点值 和 区间加区间和 问题。
树状数组¶
初步感受¶
先来举个例子:我们想知道 $a[1 \ldots 7]$ 的前缀和,怎么做?
一种做法是:$a_1 + a_2 + a_3 + a_4 + a_5 + a_6 + a_7$,需要求 $7$ 个数的和。
但是如果已知三个数 $A$,$B$,$C$,$A = a[1 \ldots 4]$ 的和,$B = a[5 \ldots 6]$ 的总和,$C = a[7 \ldots 7]$ 的总和(其实就是 $a[7]$ 自己)。你会怎么算?你一定会回答:$A + B + C$,只需要求 $3$ 个数的和。
这就是树状数组能快速求解信息的原因:我们总能将一段前缀 $[1, n]$ 拆成 不多于 $\boldsymbol{\log n}$ 段区间,使得这 $\log n$ 段区间的信息是 已知的。
于是,我们只需合并这 $\log n$ 段区间的信息,就可以得到答案。相比于原来直接合并 $n$ 个信息,效率有了很大的提高。
不难发现信息必须满足结合律,否则就不能像上面这样合并了。
下面这张图展示了树状数组的工作原理:
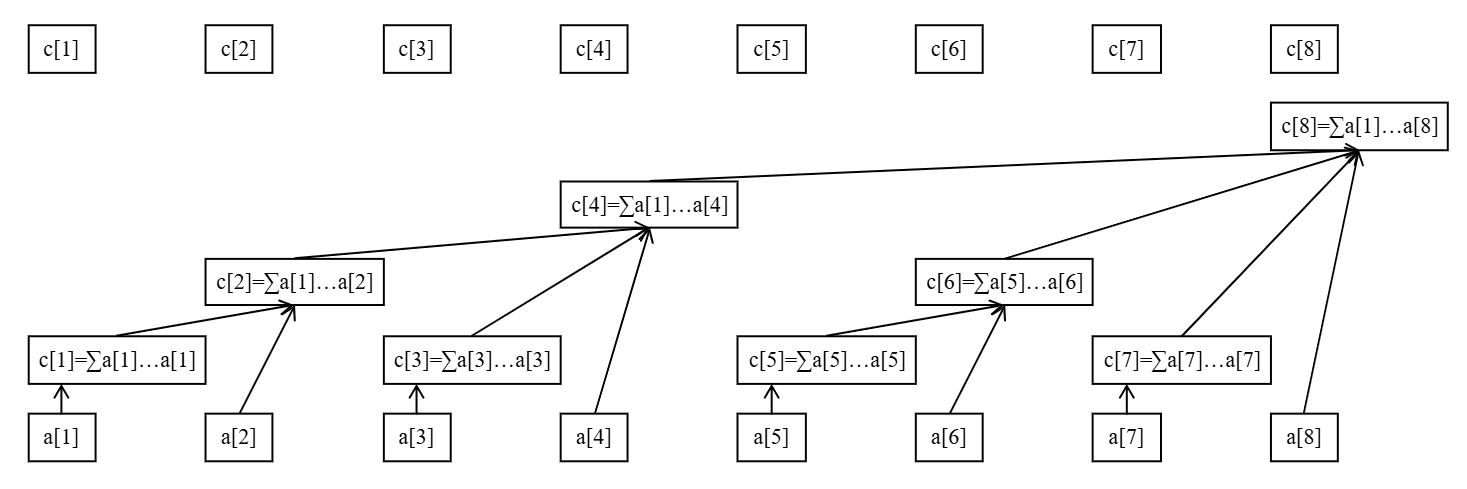
最下面的八个方块代表原始数据数组 $a$。上面参差不齐的方块(与最上面的八个方块是同一个数组)代表数组 $a$ 的上级——$c$ 数组。
$c$ 数组就是用来储存原始数组 $a$ 某段区间的和的,也就是说,这些区间的信息是已知的,我们的目标就是把查询前缀拆成这些小区间。
例如,从图中可以看出:
- $c_2$ 管辖的是 $a[1 \ldots 2]$;
- $c_4$ 管辖的是 $a[1 \ldots 4]$;
- $c_6$ 管辖的是 $a[5 \ldots 6]$;
- $c_8$ 管辖的是 $a[1 \ldots 8]$;
- 剩下的 $c[x]$ 管辖的都是 $a[x]$ 自己(可以看做 $a[x \ldots x]$ 的长度为 $1$ 的小区间)。
不难发现,$c[x]$ 管辖的一定是一段右边界是 $x$ 的区间总信息。我们先不关心左边界,先来感受一下树状数组是如何查询的。
举例:计算 $a[1 \ldots 7]$ 的和。
过程:从 $c_{7}$ 开始往前跳,发现 $c_{7}$ 只管辖 $a_{7}$ 这个元素;然后找 $c_{6}$,发现 $c_{6}$ 管辖的是 $a[5 \ldots 6]$,然后跳到 $c_{4}$,发现 $c_{4}$ 管辖的是 $a[1 \ldots 4]$ 这些元素,然后再试图跳到 $c_0$,但事实上 $c_0$ 不存在,不跳了。
我们刚刚找到的 $c$ 是 $c_7, c_6, c_4$,事实上这就是 $a[1 \ldots 7]$ 拆分出的三个小区间,合并得到答案是 $c_7 + c_6 + c_4$。
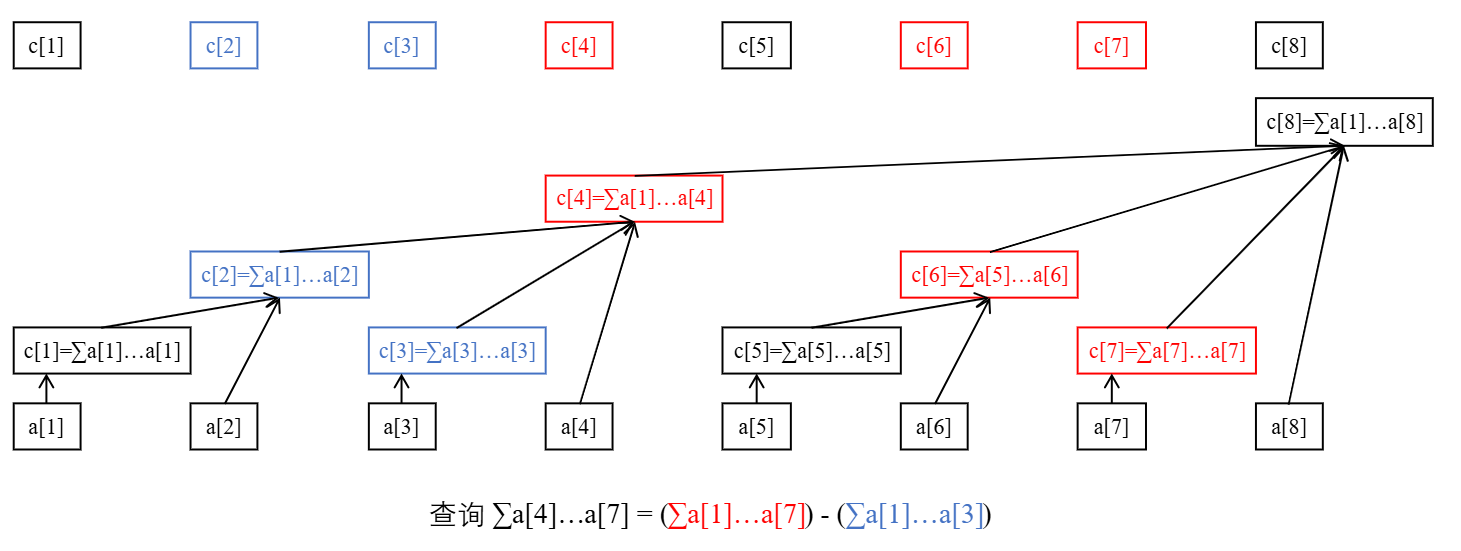
举例:计算 $a[4 \ldots 7]$ 的和。
我们还是从 $c_7$ 开始跳,跳到 $c_6$ 再跳到 $c_4$。此时我们发现它管理了 $a[1 \ldots 4]$ 的和,但是我们不想要 $a[1 \ldots 3]$ 这一部分,怎么办呢?很简单,减去 $a[1 \ldots 3]$ 的和就行了。
那不妨考虑最开始,就将查询 $a[4 \ldots 7]$ 的和转化为查询 $a[1 \ldots 7]$ 的和,以及查询 $a[1 \ldots 3]$ 的和,最终将两个结果作差。
管辖区间¶
那么问题来了,$c[x]$($x \ge 1$) 管辖的区间到底往左延伸多少?也就是说,区间长度是多少?
树状数组中,规定 $c[x]$ 管辖的区间长度为 $2^{k}$,其中:
- 设二进制最低位为第 $0$ 位,则 $k$ 恰好为 $x$ 二进制表示中,最低位的
1所在的二进制位数; - $2^k$($c[x]$ 的管辖区间长度)恰好为 $x$ 二进制表示中,最低位的
1以及后面所有0组成的数。
举个例子,$c_{88}$ 管辖的是哪个区间?
因为 $88_{(10)}=01011000_{(2)}$,其二进制最低位的 1 以及后面的 0 组成的二进制是 1000,即 $8$,所以 $c_{88}$ 管辖 $8$ 个 $a$ 数组中的元素。
因此,$c_{88}$ 代表 $a[81 \ldots 88]$ 的区间信息。
我们记 $x$ 二进制最低位 1 以及后面的 0 组成的数为 $\operatorname{lowbit}(x)$,那么 $c[x]$ 管辖的区间就是 $[x-\operatorname{lowbit}(x)+1, x]$。
注意:$\operatorname{lowbit}$ 指的不是最低位
1所在的位数 $k$,而是这个1和后面所有0组成的 $2^k$。
怎么计算 lowbit?根据位运算知识,可以得到 lowbit(x) = x & -x。
lowbit 的原理
将 x 的二进制所有位全部取反,再加 1,就可以得到 -x 的二进制编码。例如,$6$ 的二进制编码是 110,全部取反后得到 001,加 1 得到 010。
设原先 x 的二进制编码是 (...)10...00,全部取反后得到 [...]01...11,加 1 后得到 [...]10...00,也就是 -x 的二进制编码了。这里 x 二进制表示中第一个 1 是 x 最低位的 1。
(...) 和 [...] 中省略号的每一位分别相反,所以 x & -x = (...)10...00 & [...]10...00 = 10...00,得到的结果就是 lowbit。
int lowbit(int x)
{
return x & -x;
}
区间查询¶
接下来我们来看树状数组具体的操作实现,先来看区间查询。
回顾查询 $a[4 \ldots 7]$ 的过程,我们是将它转化为两个子过程:查询 $a[1 \ldots 7]$ 和查询 $a[1 \ldots 3]$ 的和,最终作差。
其实任何一个区间查询都可以这么做:查询 $a[l \ldots r]$ 的和,就是 $a[1 \ldots r]$ 的和减去 $a[1 \ldots l - 1]$ 的和,从而把区间问题转化为前缀问题,更方便处理。
事实上,将有关 $l \ldots r$ 的区间询问转化为 $1 \ldots r$ 和 $1 \ldots l - 1$ 的前缀询问再差分,在竞赛中是一个非常常用的技巧。
那前缀查询怎么做呢?回顾下查询 $a[1 \ldots 7]$ 的过程:
从 $c_{7}$ 往前跳,发现 $c_{7}$ 只管辖 $a_{7}$ 这个元素;然后找 $c_{6}$,发现 $c_{6}$ 管辖的是 $a[5 \ldots 6]$,然后跳到 $c_{4}$,发现 $c_{4}$ 管辖的是 $a[1 \ldots 4]$ 这些元素,然后再试图跳到 $c_0$,但事实上 $c_0$ 不存在,不跳了。
我们刚刚找到的 $c$ 是 $c_7, c_6, c_4$,事实上这就是 $a[1 \ldots 7]$ 拆分出的三个小区间,合并一下,答案是 $c_7 + c_6 + c_4$。
观察上面的过程,每次往前跳,一定是跳到现区间的左端点的左一位,作为新区间的右端点,这样才能将前缀不重不漏地拆分。比如现在 $c_6$ 管的是 $a[5 \ldots 6]$,下一次就跳到 $5 - 1 = 4$,即访问 $c_4$。
我们可以写出查询 $a[1 \ldots x]$ 的过程:
- 从 $c[x]$ 开始往前跳,有 $c[x]$ 管辖 $a[x-\operatorname{lowbit}(x)+1 \ldots x]$;
- 令 $x \gets x - \operatorname{lowbit}(x)$,如果 $x = 0$ 说明已经跳到尽头了,终止循环;否则回到第一步。
- 将跳到的 $c$ 合并。
实现时,我们不一定要先把 $c$ 都跳出来然后一起合并,可以边跳边合并。
比如我们要维护的信息是和,直接令初始 $\mathrm{ans} = 0$,然后每跳到一个 $c[x]$ 就 $\mathrm{ans} \gets \mathrm{ans} + c[x]$,最终 $\mathrm{ans}$ 就是所有合并的结果。
int query(int x)
{ // a[1]..a[x]的和
int ans = 0;
while (x > 0)
{
ans = ans + c[x];
x = x - lowbit(x);
}
return ans;
}
树状数组与其树形态的性质¶
在讲解单点修改之前,先讲解树状数组的一些基本性质,以及其树形态来源,这有助于更好理解树状数组的单点修改。
我们约定:
- $l(x) = x - \operatorname{lowbit}(x) + 1$。即,$l(x)$ 是 $c[x]$ 管辖范围的左端点。
- 对于任意正整数 $x$,总能将 $x$ 表示成 $s \times 2^{k + 1} + 2^k$ 的形式,其中 $\operatorname{lowbit}(x) = 2^k$。
- 下面「$c[x]$ 和 $c[y]$ 不交」指 $c[x]$ 的管辖范围和 $c[y]$ 的管辖范围不相交,即 $[l(x), x]$ 和 $[l(y), y]$ 不相交。「$c[x]$ 包含于 $c[y]$」等表述同理。
性质 $\boldsymbol{1}$:对于 $\boldsymbol{x \le y}$,要么有 $\boldsymbol{c[x]}$ 和 $\boldsymbol{c[y]}$ 不交,要么有 $\boldsymbol{c[x]}$ 包含于 $\boldsymbol{c[y]}$。
证明:假设 $c[x]$ 和 $c[y]$ 相交,即 $[l(x), x]$ 和 $[l(y), y]$ 相交,则一定有 $l(y) \le x \le y$。
将 $y$ 表示为 $s \times 2^{k +1} + 2^k$,则 $l(y) = s \times 2^{k + 1} + 1$。所以,$x$ 可以表示为 $s \times 2^{k +1} + b$,其中 $1 \le b \le 2^k$。
不难发现 $\operatorname{lowbit}(x) = \operatorname{lowbit}(b)$。又因为 $b - \operatorname{lowbit}(b) \ge 0$,
所以 $l(x) = x - \operatorname{lowbit}(x) + 1 = s \times 2^{k +1} + b - \operatorname{lowbit}(b) +1 \ge s \times 2^{k +1} + 1 = l(y)$,即 $l(y) \le l(x) \le x \le y$。
所以,如果 $c[x]$ 和 $c[y]$ 相交,那么 $c[x]$ 的管辖范围一定完全包含于 $c[y]$。
性质 $\boldsymbol{2}$:$\boldsymbol{c[x]}$ 真包含于 $\boldsymbol{c[x + \operatorname{lowbit}(x)]}$。
证明:设 $y = x + \operatorname{lowbit}(x)$,$x = s \times 2^{k + 1} + 2^k$,则 $y = (s + 1) \times 2^{k +1}$,$l(x) = s \times 2^{k + 1} + 1$。
不难发现 $\operatorname{lowbit}(y) \ge 2^{k + 1}$,所以 $l(y) = (s + 1) \times 2^{k + 1} - \operatorname{lowbit}(y) + 1 \le s \times 2^{k +1} + 1= l(x)$,即 $l(y) \le l(x) \le x < y$。
所以,$c[x]$ 真包含于 $c[x + \operatorname{lowbit}(x)]$。
性质 $3$:对于任意 $\boldsymbol{x < y < x + \operatorname{lowbit}(x)}$,有 $\boldsymbol{c[x]}$ 和 $\boldsymbol{c[y]}$ 不交。
证明:设 $x = s \times 2^{k + 1} + 2^k$,则 $y = x + b = s \times 2^{k + 1} + 2^k + b$,其中 $1 \le b < 2^k$。
不难发现 $\operatorname{lowbit}(y) = \operatorname{lowbit}(b)$。又因为 $b - \operatorname{lowbit}(b) \ge 0$,
因此 $l(y) = y - \operatorname{lowbit}(y) + 1 = x + b - \operatorname{lowbit}(b) + 1 > x$,即 $l(x) \le x < l(y) \le y$。
所以,$c[x]$ 和 $c[y]$ 不交。
有了这三条性质的铺垫,我们接下来看树状数组的树形态(请忽略 $a$ 向 $c$ 的连边)。
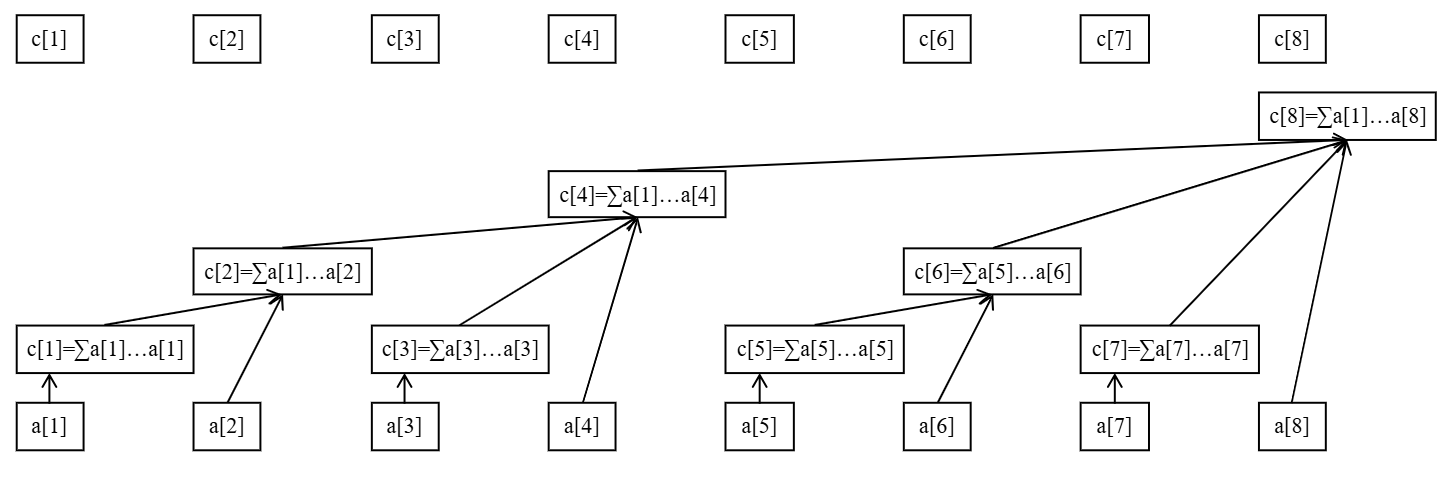
事实上,树状数组的树形态是 $x$ 向 $x + \operatorname{lowbit}(x)$ 连边得到的图,其中 $x + \operatorname{lowbit}(x)$ 是 $x$ 的父亲。
单点修改¶
现在来考虑如何单点修改 $a[x]$。
我们的目标是快速正确地维护 $c$ 数组。为保证效率,我们只需遍历并修改管辖了 $a[x]$ 的所有 $c[y]$,因为其他的 $c$ 显然没有发生变化。
管辖 $a[x]$ 的 $c[y]$ 一定包含 $c[x]$(根据性质 $1$),所以 $y$ 在树状数组树形态上是 $x$ 的祖先。因此我们从 $x$ 开始不断跳父亲,直到跳得超过了原数组长度为止。
设 $n$ 表示 $a$ 的大小,不难写出单点修改 $a[x]$ 的过程:
- 初始令 $x' = x$。
- 修改 $c[x']$。
- 令 $x' \gets x' + \operatorname{lowbit}(x')$,如果 $x' > n$ 说明已经跳到尽头了,终止循环;否则回到第二步。
区间信息和单点修改的种类,共同决定 $c[x']$ 的修改方式。下面给几个例子:
- 若 $c[x']$ 维护区间和,修改种类是将 $a[x]$ 加上 $p$,则修改方式则是将所有 $c[x']$ 也加上 $p$。
- 若 $c[x']$ 维护区间积,修改种类是将 $a[x]$ 乘上 $p$,则修改方式则是将所有 $c[x']$ 也乘上 $p$。
然而,单点修改的自由性使得修改的种类和维护的信息不一定是同种运算,比如,若 $c[x']$ 维护区间和,修改种类是将 $a[x]$ 赋值为 $p$,可以考虑转化为将 $a[x]$ 加上 $p - a[x]$。如果是将 $a[x]$ 乘上 $p$,就考虑转化为 $a[x]$ 加上 $a[x] \times p - a[x]$。
下面以维护区间和,单点加为例给出实现。
#include <bits/stdc++.h>
using namespace std;
using i64 = long long;
constexpr int N = 1e6 + 5;
i64 n, q, a[N], c[N];
int lowbit(int x)
{
return x & (-x);
}
void add(int x, i64 k)
{
for (int i = x; i <= n; i += lowbit(i))
c[i] += k;
}
i64 query(int x)
{
i64 res = 0;
for (int i = x; i >= 1; i -= lowbit(i))
res += c[i];
return res;
}
i64 query(int l, int r) // 函数的重载,同名参数不同可以用 或返回值不同
{
return query(r) - query(l - 1);
}
int main()
{
ios::sync_with_stdio(false), cin.tie(0);
cin >> n >> q;
for (int i = 1; i <= n; i++)
{
cin >> a[i];
add(i, a[i]); // 初始化
}
while (q--)
{
int op;
cin >> op;
if (op == 1)
{
int i, x;
cin >> i >> x;
add(i, x);
}
else
{
int l, r;
cin >> l >> r;
cout << query(r) - query(l - 1) << "\n";
}
}
return 0;
}
建树¶
也就是根据最开始给出的序列,将树状数组建出来($c$ 全部预处理好)。
一般可以直接转化为 $n$ 次单点修改,时间复杂度 $\Theta(n \log n)$(复杂度分析在后面)。
比如给定序列 $a = (5, 1, 4)$ 要求建树,直接看作对 $a[1]$ 单点加 $5$,对 $a[2]$ 单点加 $1$,对 $a[3]$ 单点加 $4$ 即可。
也有 $\Theta(n)$ 的建树方法。
复杂度分析¶
空间复杂度显然 $\Theta(n)$。
时间复杂度:
- 对于区间查询操作:整个 $x \gets x - \operatorname{lowbit}(x)$ 的迭代过程,可看做将 $x$ 二进制中的所有 $1$,从低位到高位逐渐改成 $0$ 的过程,拆分出的区间数等于 $x$ 二进制中 $1$ 的数量(即 $\operatorname{popcount}(x)$)。因此,单次查询时间复杂度是 $\Theta(\log n)$;
- 对于单点修改操作:跳父亲时,访问到的高度一直严格增加,且始终有 $x \le n$。由于点 $x$ 的高度是 $\log_2\operatorname{lowbit}(x)$,所以跳到的高度不会超过 $\log_2n$,所以访问到的 $c$ 的数量是 $\log n$ 级别。因此,单次单点修改复杂度是 $\Theta(\log n)$。
区间加区间和¶
前置知识:[前缀和 & 差分]。
该问题可以使用两个树状数组维护差分数组解决。
考虑序列 $a$ 的差分数组 $d$,其中 $d[i] = a[i] - a[i - 1]$。由于差分数组的前缀和就是原数组,所以 $a_i=\sum_{j=1}^i d_j$。
一样地,我们考虑将查询区间和通过差分转化为查询前缀和。那么考虑查询 $a[1 \ldots r]$ 的和,即 $\sum_{i=1}^{r} a_i$,进行推导:
观察这个式子,不难发现每个 $d_j$ 总共被加了 $r - j + 1$ 次。接着推导:
$\sum_{i=1}^r d_i$ 并不能推出 $\sum_{i=1}^r d_i \times i$ 的值,所以要用两个树状数组分别维护 $d_i$ 和 $d_i \times i$ 的和信息。
那么怎么做区间加呢?考虑给原数组 $a[l \ldots r]$ 区间加 $x$ 给 $d$ 带来的影响。
因为差分是 $d[i] = a[i] - a[i - 1]$,
- $a[l]$ 多了 $v$ 而 $a[l - 1]$ 不变,所以 $d[l]$ 的值多了 $v$。
- $a[r + 1]$ 不变而 $a[r]$ 多了 $v$,所以 $d[r + 1]$ 的值少了 $v$。
- 对于不等于 $l$ 且不等于 $r+1$ 的任意 $i$,$a[i]$ 和 $a[i - 1]$ 要么都没发生变化,要么都加了 $v$,$a[i] + v - (a[i - 1] + v)$ 还是 $a[i] - a[i - 1]$,所以其它的 $d[i]$ 均不变。
那就不难想到维护方式了:对于维护 $d_i$ 的树状数组,对 $l$ 单点加 $v$,$r + 1$ 单点加 $-v$;对于维护 $d_i \times i$ 的树状数组,对 $l$ 单点加 $v \times l$,$r + 1$ 单点加 $-v \times (r + 1)$。
而更弱的问题,「区间加求单点值」,只需用树状数组维护一个差分数组 $d_i$。询问 $a[x]$ 的单点值,直接求 $d[1 \ldots x]$ 的和即可。
这里直接给出「区间加区间和」的代码:
struct tree
{
int c[N];
int lowbit(int x) { return x & -x; }
void add(int x, int k)
{
for (int i = x; i <= n; i += lowbit(i))
{
c[i] += k;
}
}
int query(int x)
{
int res = 0;
for (int i = x; i >= 1; i -= lowbit(i))
{
res += c[i];
}
return res;
}
} t1, t2;
void add(int i, int x)
{
t1.add(i, x);
t2.add(i, x * i);
}
int query(int x)
{
return (x + 1) * t1.query(x) - t2.query(x);
}
signed main()
{
ios::sync_with_stdio(false);
cin.tie(0);
cin >> n >> q;
for (int i = 1; i <= n; i++)
{
cin >> a[i];
}
for (int i = 1; i <= n; i++)
{
b[i] = a[i] - a[i - 1];
t1.add(i, b[i]);
t2.add(i, b[i] * i);
}
while (q--)
{
int op;
cin >> op;
if (op == 1)
{
int l, r, x;
cin >> l >> r >> x;
add(l, x);
add(r + 1, -x);
}
else if (op == 2)
{
int l, r;
cin >> l >> r;
cout << query(r) - query(l - 1) << '\n';
}
}
return 0;
}
根据这个原理,应该可以实现「区间乘区间积」,「区间异或一个数,求区间异或值」等,只要满足维护的信息和区间操作是同种运算即可,感兴趣的读者可以自己尝试。
二维树状数组¶
单点修改,子矩阵查询¶
二维树状数组,也被称作树状数组套树状数组,用来维护二维数组上的单点修改和前缀信息问题。
与一维树状数组类似,我们用 $c(x, y)$ 表示
的矩阵总信息,即一个以 $a(x, y)$ 为右下角,高 $\operatorname{lowbit}(x)$,宽 $\operatorname{lowbit}(y)$ 的矩阵的总信息。
void add(int x, int y, int v)
{
for (int i = x; i <= n; i += lowbit(i))
for (int j = y; j <= m; j += lowbit(j))
c[i][j] += v;
}
int query(int x, int y)
{
int res = 0;
for (int i = x; i; i -= lowbit(i))
for (int j = y; j; j -= lowbit(j))
res += c[i][j];
return res;
}
int query(int x1, int y1, int x2, int y2)
{
return query(x2, y2) - query(x1 - 1, y2) - query(x2, y1 - 1) + query(x1 - 1, y1 - 1);
}
子矩阵加,单点查询¶
使用二维差分将子矩阵加转化为四次单点修改,将单点修改转化到二维差分上的前缀查询。
子矩阵加,求子矩阵和¶
前置知识:[前缀和 & 差分] 和本页面 [区间加区间和] 一节。
和一维树状数组的「区间加区间和」问题类似,考虑维护差分数组。
二维数组上的差分数组是这样的:
为什么这么定义?
这是因为,理想规定状态下,在差分矩阵上做二维前缀和应该得到原矩阵,因为这是一对逆运算。
二维前缀和的公式是这样的:
$s(i, j) = s(i - 1, j) + s(i, j - 1) - s(i - 1, j - 1) + a(i, j)$。
所以,设 $a$ 是原数组,$d$ 是差分数组,有:
$a(i, j) = a(i - 1, j) + a(i, j - 1) - a(i - 1, j - 1) + d(i, j)$
移项就得到二维差分的公式了。
$d(i, j) = a(i, j) - a(i - 1, j) - a(i, j - 1) + a(i - 1, j - 1)$。
这样以来,对左上角 $(x_1, y_1)$,右下角 $(x_2, y_2)$ 的子矩阵区间加 $v$,相当于在差分数组上,对 $d(x_1, y_1)$ 和 $d(x_2 + 1, y_2 + 1)$ 分别单点加 $v$,对 $d(x_2 + 1, y_1)$ 和 $d(x_1, y_2 + 1)$ 分别单点加 $-v$。
至于原因,把这四个 $d$ 分别用定义式表示出来,分析一下每项的变化即可。
举个例子吧,初始差分数组为 $0$,给 $a(2, 2) \ldots a(3, 4)$ 子矩阵加 $v$ 后差分数组会变为:
(其中 $a(2, 2) \ldots a(3, 4)$ 这个子矩阵恰好是上面位于中心的 $2 \times 3$ 大小的矩阵。)
因此,子矩阵加的做法是:转化为差分数组上的四个单点加操作。
现在考虑查询子矩阵和:
对于点 $(x, y)$,它的二维前缀和可以表示为:
原因就是差分的前缀和的前缀和就是原本的前缀和。
和一维树状数组的「区间加区间和」问题类似,统计 $d(h, k)$ 的出现次数,为 $(x - h + 1) \times (y - k + 1)$。
然后接着推导:
所以我们需维护四个树状数组,分别维护 $d(i, j)$,$d(i, j) \times i$,$d(i, j) \times j$,$d(i, j) \times i \times j$ 的和信息。
当然了,和一维同理,如果只需要子矩阵加求单点值,维护一个差分数组然后询问前缀和就足够了。
下面给出代码:
#include <bits/stdc++.h>
#define int long long
using namespace std;
constexpr int N = 2048 + 5;
int n, m;
struct tree
{
int c[N][N];
int lowbit(int x) { return x & -x; }
void add(int x, int y, int v)
{
for (int i = x; i <= n; i += lowbit(i))
for (int j = y; j <= m; j += lowbit(j))
c[i][j] += v;
}
int query(int x, int y)
{
int res = 0;
for (int i = x; i >= 1; i -= lowbit(i))
for (int j = y; j >= 1; j -= lowbit(j))
res += c[i][j];
return res;
}
} tr[4];
void add(int x, int y, int v)
{
tr[0].add(x, y, v);
tr[1].add(x, y, v * y);
tr[2].add(x, y, v * x);
tr[3].add(x, y, v * x * y);
}
int query(int x, int y)
{
return tr[0].query(x, y) * (x * y + x + y + 1) - tr[1].query(x, y) * (x + 1) - tr[2].query(x, y) * (y + 1) + tr[3].query(x, y);
}
signed main()
{
ios::sync_with_stdio(false), cin.tie(0);
cin >> n >> m;
int op = 0;
while (cin >> op)
{
int x1, y1, x2, y2, v;
cin >> x1 >> y1 >> x2 >> y2;
if (op == 1)
{
cin >> v;
add(x1, y1, v);
add(x1, y2 + 1, -v);
add(x2 + 1, y1, -v);
add(x2 + 1, y2 + 1, v);
}
else
{
int ans = query(x2, y2) - query(x1 - 1, y2) - query(x2, y1 - 1) + query(x1 - 1, y1 - 1);
cout << ans << '\n';
}
}
return 0;
}
权值树状数组及应用¶
我们知道,普通树状数组直接在原序列的基础上构建,$c_6$ 表示的就是 $a[5 \ldots 6]$ 的区间信息。
然而事实上,我们还可以在原序列的权值数组上构建树状数组,这就是权值树状数组。
什么是权值数组?
一个序列 $a$ 的权值数组 $b$,满足 $b[x]$ 的值为 $x$ 在 $a$ 中的出现次数。
例如:$a = (1, 3, 4, 3, 4)$ 的权值数组为 $b = (1, 0, 2, 2)$。
很明显,$b$ 的大小和 $a$ 的值域有关。
若原数列值域过大,且重要的不是具体值而是值与值之间的相对大小关系,常 [离散化] 原数组后再建立权值数组。
另外,权值数组是原数组无序性的一种表示:它重点描述数组的元素内容,忽略了数组的顺序,若两数组只是顺序不同,所含内容一致,则它们的权值数组相同。
因此,对于给定数组的顺序不影响答案的问题,在权值数组的基础上思考一般更直观。
运用权值树状数组,我们可以解决一些经典问题。
全局逆序对(全局二维偏序)¶
全局逆序对也可以用权值树状数组巧妙解决。问题是这样的:给定长度为 $n$ 的序列 $a$,求 $a$ 中满足 $i < j$ 且 $a[i] > a[j]$ 的数对 $(i, j)$ 的数量。
该问题可离散化,如果原序列 $a$ 值域过大,离散化后再建立权值数组 $b$。
我们考虑从 $n$ 到 $1$ 倒序枚举 $i$,作为逆序对中第一个元素的索引,然后计算有多少个 $j > i$ 满足 $a[j] < a[i]$,最后累计答案即可。
事实上,我们只需要这样做(设当前 $a[i] = x$):
- 查询 $b[1 \ldots x - 1]$ 的前缀和,即为左端点为 $a[i]$ 的逆序对数量。
- $b[x]$ 自增 $1$;
原因十分自然:出现在 $b[1 \ldots x-1]$ 中的元素一定比当前的 $x = a[i]$ 小,而 $i$ 的倒序枚举,自然使得这些已在权值数组中的元素,在原数组上的索引 $j$ 大于当前遍历到的索引 $i$。
用例子说明,$a = (4, 3, 1, 2, 1)$。
$i$ 按照 $5 \to 1$ 扫:
- $a[5] = 1$,查询 $b[1 \ldots 0]$ 前缀和,为 $0$,$b[1]$ 自增 $1$,$b = (1, 0, 0, 0)$。
- $a[4] = 2$,查询 $b[1 \ldots 1]$ 前缀和,为 $1$,$b[2]$ 自增 $1$,$b = (1, 1, 0, 0)$。
- $a[3] = 1$,查询 $b[1 \ldots 0]$ 前缀和,为 $0$,$b[1]$ 自增 $1$,$b = (2, 1, 0, 0)$。
- $a[2] = 3$,查询 $b[1 \ldots 2]$ 前缀和,为 $3$,$b[3]$ 自增 $1$,$b = (2, 1, 1, 0)$。
- $a[1] = 4$,查询 $b[1 \ldots 3]$ 前缀和,为 $4$,$b[4]$ 自增 $1$,$b = (2, 1, 1, 1)$。
所以最终答案为 $0 + 1 + 0 + 3 + 4 = 8$。
注意到,遍历 $i$ 后的查询 $b[1 \ldots x - 1]$ 和自增 $b[x]$ 的两个步骤可以颠倒,变成先自增 $b[x]$ 再查询 $b[1 \ldots x - 1]$,不影响答案。两个角度来解释:
- 对 $b[x]$ 的修改不影响对 $b[1 \ldots x - 1]$ 的查询。
- 颠倒后,实质是在查询 $i \le j$ 且 $a[i] > a[j]$ 的数对数量,而 $i = j$ 时不存在 $a[i] > a[j]$,所以 $i \le j$ 相当于 $i < j$,所以这与原来的逆序对问题是等价的。
如果查询非严格逆序对($i < j$ 且 $a[i] \ge a[j]$)的数量,那就要改为查询 $b[1 \ldots x]$ 的和,这时就不能颠倒两步了,还是两个角度来解释:
- 对 $b[x]$ 的修改 影响 对 $b[1 \ldots x]$ 的查询。
- 颠倒后,实质是在查询 $i \le j$ 且 $a[i] \ge a[j]$ 的数对数量,而 $i = j$ 时恒有 $a[i] \ge a[j]$,所以 $i \le j$ 不相当于 $i < j$,与原问题 不等价。
如果查询 $i \le j$ 且 $a[i] \ge a[j]$ 的数对数量,那这两步就需要颠倒了。
另外,对于原逆序对问题,还有一种做法是正着枚举 $j$,查询有多少 $i < j$ 满足 $a[i] > a[j]$。做法如下(设 $x = a[j]$):
- 查询 $b[x + 1 \ldots V]$($V$ 是 $b$ 的大小,即 $a$ 的值域(或离散化后的值域))的区间和。
- 将 $b[x]$ 自增 $1$。
原因:出现在 $b[x + 1 \ldots V]$ 中的元素一定比当前的 $x = a[j]$ 大,而 $j$ 的正序枚举,自然使得这些已在权值数组中的元素,在原数组上的索引 $i$ 小于当前遍历到的索引 $j$。
此外,逆序对的计数还可以通过 [归并排序] 解决。这一方法可以避免离散化。时间复杂度同样为 $O(n\log n)$。
#include <bits/stdc++.h>
using namespace std;
using i64 = long long;
constexpr int N = 5e5 + 5;
int n, a[N], lsh[N];
struct tree
{
int n;
vector<int> c;
tree(int _n) : n(_n), c(_n + 1) {}
int lowbit(int x) { return x & -x; }
void add(int x, int k)
{
for (int i = x; i <= n; i += lowbit(i))
{
c[i] += k;
}
}
int query(int x)
{
int res = 0;
for (int i = x; i >= 1; i -= lowbit(i))
{
res += c[i];
}
return res;
}
int query(int l, int r) { return query(r) - query(l - 1); }
};
int main()
{
ios::sync_with_stdio(false), cin.tie(0);
cin >> n;
for (int i = 1; i <= n; i++)
{
cin >> a[i];
lsh[i] = a[i];
}
sort(lsh + 1, lsh + n + 1);
int m = unique(lsh + 1, lsh + n + 1) - (lsh + 1);
tree t(m); // 离散化后值域为 [1, m]
i64 ans = 0;
for (int i = 1; i <= n; i++)
{
int id = lower_bound(lsh + 1, lsh + m + 1, a[i]) - lsh;
ans += t.query(id + 1, m);
t.add(id, 1);
}
cout << ans;
return 0;
}
Tricks¶
$\Theta(n)$ 建树¶
以维护区间和为例。
方法一:
每一个节点的值是由所有与自己直接相连的儿子的值求和得到的。因此可以倒着考虑贡献,即每次确定完儿子的值后,用自己的值更新自己的直接父亲。
// Θ(n) 建树
void init()
{
for (int i = 1; i <= n; ++i)
{
c[i] += a[i];
int j = i + lowbit(i);
if (j <= n)
{
c[j] += c[i];
}
}
}
方法二:
前面讲到 $c[i]$ 表示的区间是 $[i-\operatorname{lowbit}(i)+1, i]$,那么我们可以先预处理一个 $\mathrm{sum}$ 前缀和数组,再计算 $c$ 数组。
// Θ(n) 建树
void init()
{
for (int i = 1; i <= n; ++i)
{
c[i] = sum[i] - sum[i - lowbit(i)];
}
}